![How to Validate Transcription Accuracy in Qualitative Research? [Checklist Included]](/sanity-images/ejgwz1gl/redesign/eb4d668bc95b38859cee00050ec27a38d3e8a075-1536x1024.jpg?auto=format&w=1536.0&rect=0,128,1536,768&h=768)
A missed context in a transcript can quickly change a research finding. If a participant says "I never felt supported," and it gets transcribed as "I always felt supported," that can distort a theme and shape a conclusion not supported by your data.
In qualitative research, everything downstream depends on what's in the transcript. That's why validation is a methodological requirement, and it ensures your research can withstand peer scrutiny.
This guide covers how to validate transcription accuracy in qualitative research: the error types that compromise validity, a step-by-step validation process, how AI transcription changes that workflow, and a practical checklist you can apply from your next project onward.
Why transcription accuracy matters in qualitative research
In qualitative research, the transcript is the primary dataset for you to work with. Unlike quantitative research, where raw data can be extracted from statistics, qualitative findings emerge from the words participants actually used, the phrasing they chose, the hesitations they had, and the way they framed ideas.
1. Transcription errors can spread undetected
The problem with small errors is that they dont don't stay contained. For example, a substitution error can flip the valence of a statement, and an omission strips context from a quote that would otherwise lead to a theme.
If you misattribute speakers in a focus group, you end up coding the wrong person's perspective into your analysis. The errors occur more frequently than you think, and they creep in silently.
2. You're responsible for representing participants' voices faithfully
There's an ethical dimension that researchers sometimes underestimate. Participants share their time, their experiences, and often their trust in surveys. When a transcript misrepresents what they said, it replaces their voice with an approximation.
In research that focuses on lived experiences, that approximation is a failure of your ethical responsibility to the people who contributed to your study.
3. Accurate transcripts serve as a defensible audit trail
If a journal reviewer or dissertation examiner asks to trace how your themes emerged from your data, your transcripts are the first thing they'll check.
An inaccurate transcript not only weakens that chain, but it also makes the entire analytical process questionable.
Types of transcription errors that compromise research validity
Not all transcription errors look the same, and some are harder to catch than others. Before you can validate a transcript, you need to know what you're looking for.
- Substitutions happen when one word replaces another. These are the most dangerous because they can change meaning without looking wrong on the page
- Omissions occur when words or phrases drop out of the transcript entirely. A deleted clause can strip a participant's statement of nuance or qualification
- Insertions are the opposite: words added that were never spoken. They creep in when a transcriber fills in what they think was said during an unclear passage
- Contextual errors involve missed non-verbal cues like pauses, laughter, or vocal emphasis. In verbatim transcription, these carry analytical weight, and their absence can flatten the data
- Speaker misattribution assigns a statement to the wrong participant. In multi-speaker recordings like focus groups, this corrupts your coding at the source
- Bias-introduced errors occur when a transcriber's interpretation overrides what was actually said. This occurs more when the content is ambiguous, and the transcriber defaults to what sounds "right" rather than what was spoken
How to validate transcription accuracy: Step-by-step guide
1. Conduct a full audio-text comparison
Play the full recording while reading the transcript from start to finish. This is where you flag every discrepancy between what was said and what was transcribed.
Pay close attention to sections with overlapping speech, low audio quality, or emotionally charged responses, since these are where errors cluster.
If you're working in an interactive transcript editor, you can save a lot of time here. The editor highlights text in sync with audio playback, color-codes speakers, and lets you adjust playback speed so you can follow multi-participant recordings without losing track.
2. Use Word Error Rate (WER) for quantitative benchmarking
WER gives you a numeric measure of transcription accuracy. The formula is simple: (substitutions + insertions + deletions) / total words in the reference transcript. A WER of 0.05 means 5% of words contain errors.
WER is a key metric when you're benchmarking AI-generated transcripts before human review. Run WER on a sample, identify the threshold your research can tolerate, and use the result to decide how much manual correction is needed. WER won't catch contextual errors or missed non-verbal cues, so treat it as a first-pass filter.
3. Perform member checking
Member checking involves sending transcripts back to participants so they can review what was captured. It's one of four credibility techniques in Lincoln and Guba's trustworthiness framework, alongside prolonged engagement, peer debriefing, and triangulation.
The benefit is obvious: participants can catch errors you wouldn't, especially around intent, emphasis, or culturally specific language. But there are limitations you should remember. Some participants feel embarrassed when they see their spoken language in writing, while others might want to retract or soften statements they made in the moment. Build these possibilities into your protocol, so you have a clear process for handling revisions versus retractions.
4. Use peer debriefing and independent review
A fresh set of eyes can help you overcome biases. Have a second researcher or colleague review a sample of transcripts against the original audio, focusing on passages that are critical to your coding. If two reviewers flag different errors in the same section, that's a signal the passage needs a closer look.
This step also functions as a reliability check. When independent reviewers agree on transcript accuracy, it strengthens the credibility of your dataset.
5. Standardize a transcription protocol
If you’re working with a team, define your notation conventions before anyone starts transcribing. This includes how you'll mark pauses, overlapping speech, inaudible segments, and emotional tone. Without a shared protocol, inconsistencies across transcripts become inevitable, especially in team-based projects.
Eftekhari (2024) outlines a practical framework for transcription protocols in qualitative research, including how to handle the transition from manual to AI-assisted workflows. If your team is splitting transcription across multiple people, a documented protocol will keep your data consistent.
6. Run consistency checks across transcripts
Once individual transcripts are validated, check for consistency across your full dataset. Verify participant names, place names, technical terms, speaker labels, and timestamps to make sure everything aligns with the audio.
These checks are tedious, but they prevent confusion during coding and make your audit trail easier to follow.
AI transcription and validation: How the workflow changes
Did you know? According to McKinsey research, 79% orgnizations use generative AI to speed up work.
AI transcription has changed how researchers handle qualitative data. The core workflow is different, and so are the errors you need to watch for.
- AI produces a first draft in minutes instead of hours, but its errors are harder to catch. AI-generated text is grammatically fluent, so a substituted word can look correct on the page while changing the meaning of a statement
- The emerging standard for research transcription is an AI+human workflow. AI generates the transcript, and a human reviewer validates it against the original audio. Neither step replaces the other
- Human verification still needs to follow the same validation steps outlined above: full audio-text comparison, member checking where appropriate, and consistency checks across transcripts
- If you're using a cloud-based AI tool, your IRB, REC, IEC, or regional ethics board will likely require you to disclose that in your forms. Before committing to a platform, confirm where your data is stored, whether files are encrypted in transit and at rest, and what compliance certifications the provider holds
Tools that help you improve transcription accuracy in research
HappyScribe
For qualitative researchers, the core problem is that transcription is both time-intensive and high-stakes. HappyScribe is built for researchers who want speed and flexibility without sacrificing accuracy.
With API, MCP server, and Zapier integrations and support for translation and subtitling, HappyScribe helps you extend research workflows without paying for more tools.
AI and human transcription options
With HappyScribe, you can run AI transcriptions in 150+ languages to generate a first-pass transcript in minutes. When your project requires verified accuracy, you can send the media file or transcript to an expert linguist who brings it to 99% accuracy. For qualitative researchers, this means you don't have to choose between speed and accuracy and can work with both AI and human experts.
Interactive transcript editor
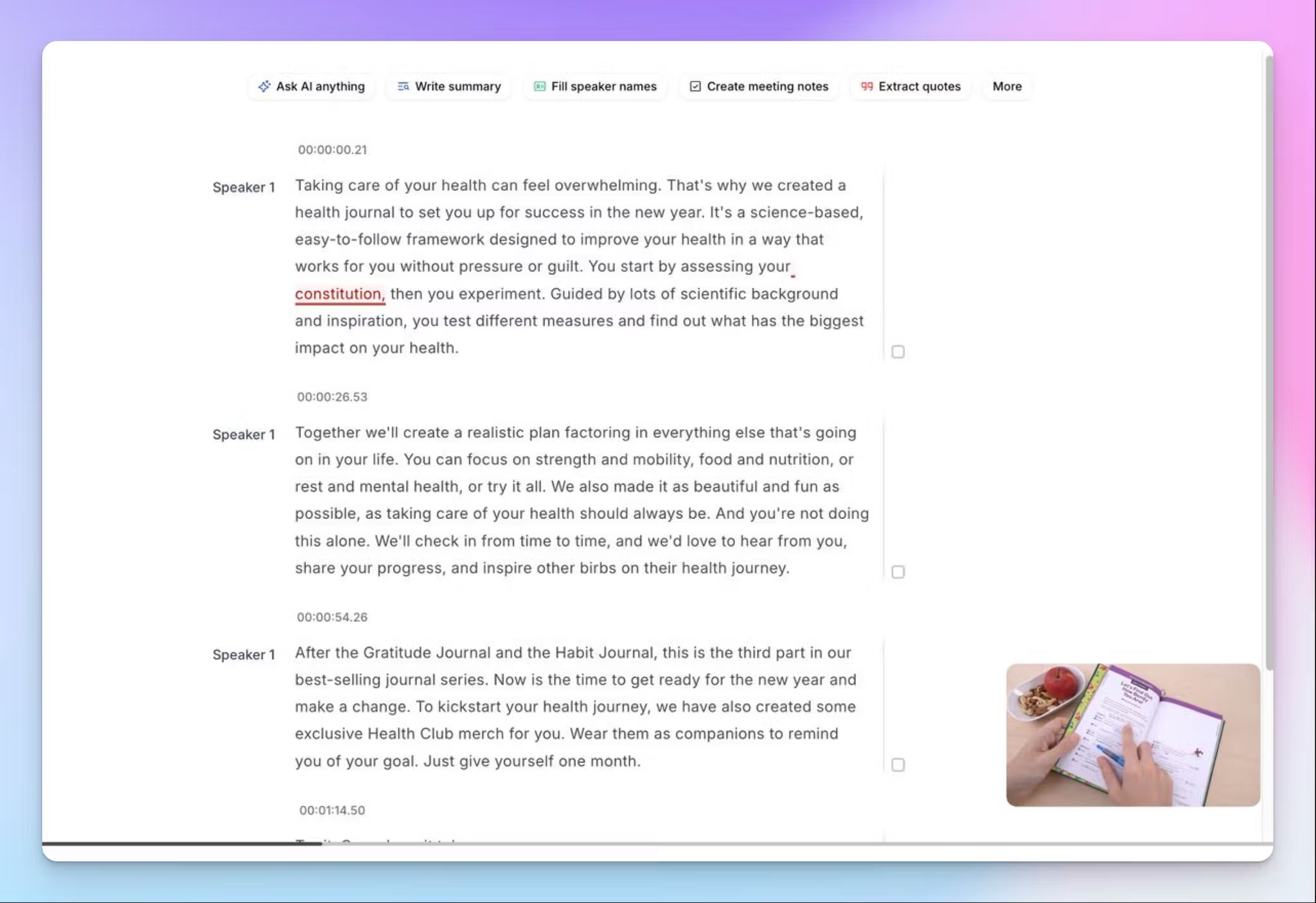
The validation process I outlined earlier depends on being able to compare audio against text efficiently. HappyScribe's editor allows you to listen and read simultaneously, adjust playback speed, search terms, highlight passages, and correct errors directly in the text. You can also invite team members, which is useful for larger projects that go through several rounds of verification.
Find deeper insights with AI Chat

Once you have all the transcript data, you can use HappyScribe AI Chat to surface key insights, observations, and patterns you might have missed while reviewing the transcripts. The AI Chat is built for deep conversations, so you can ask it to scan all files and help you with summaries, drafts, and quotes.
Speaker detection and timestamps
HappyScribe automatically identifies and labels speakers throughout the transcript. Since timestamps are attached at the word level, you can cross-reference any passage against the original audio without scrubbing through the full recording.
GDPR-compliant and SOC 2 Type II certified
If you're submitting an ethics application or IRB protocol that involves cloud-based transcription, you might be asked how participant data is stored and protected. HappyScribe holds SOC 2 Type II certification, which means it’s audited by an independent team for regular security and system integrity.
Thanks to GDPR compliance and EU-based data storage, participants have more control over privacy and consent. Having these certifications documented upfront makes the ethics approval process more straightforward.
Other tools worth considering for qualitative research
1. ATLAS.ti
ATLAS.ti is a qualitative data analysis tool. It handles coding, theme identification, and network visualization once you already have a clean transcript to work with. If you're using HappyScribe or another transcription tool to generate and verify your transcripts, ATLAS.ti might be useful for the analysis.
2. Otter
Otter is an AI-powered transcription tool built primarily for meetings. It records conversions on Zoom, Google Meet, and Microsoft Teams, generates transcripts, and produces AI summaries.
Having said that, Otter supports only 6 languages, which is a significant constraint for users working with multilingual interview data. The Pro plan starts at $16.99/month but caps you at 1,200 minutes and 10 file imports per month, so large databases of pre-recorded interviews are off limits.
3. Rev
Rev’s core strength is human-made transcription with 99% claimed accuracy and a typical turnaround of 12-24 hours, which makes it a reliable option for researchers who want a fully human workflow. Rev also offers AI transcription and file analysis. Keep in mind that Rev isn’t the most affordable option out there, and if you work on heavy projects, bills add up quickly.
Transcription accuracy checklist for qualitative researchers
Use this checklist as a quick reference before, during, and after transcription. Each step is covered in detail earlier in this guide.
| Phase | Action |
|---|---|
| Before transcription |
|
| During transcription |
|
| After transcription |
|
Validate your transcripts before you build on them
Transcription validation isn't something you do once and forget about it. It's a layered process where each step catches what the previous one missed.
A full audio-text comparison picks up errors that WER can't quantify, and member checking surfaces misrepresentations that even a careful reviewer won't catch. By running consistency checks across the dataset, you prevent small discrepancies from compounding during coding.
But a thorough process only works if your tools support it. If you're switching between a transcription service, a separate audio player, and a spreadsheet to track corrections, validation takes longer and errors slip through the gaps between tools.
HappyScribe brings transcription, verification, and collaboration into one platform. You can generate AI transcripts, escalate to human proofreading when accuracy is critical, and run your entire validation workflow inside the editor.
FAQs on how to validate transcription accuracy in qualitative research
What is member checking in transcription validation?
Member checking is when you send transcripts back to participants so they can review what was captured during the interview process. It's a credibility technique found in Lincoln and Guba's trustworthiness framework, and it helps you catch errors related to intent, emphasis, or culturally specific language that a reviewer might miss. The limitation is that some participants feel uncomfortable seeing their spoken language in written form, and others may want to retract statements.
Build a clear protocol for handling these situations before you start the transcription process, so you're not making ad hoc decisions about revisions while the qualitative research transcription is underway. Member checking also reduces potential biases that can creep in when a single researcher controls how all the interviews are represented.
How do you calculate Word Error Rate (WER) for a transcript?
WER measures how far a transcript deviates from a reference version. The formula is (substitutions + insertions + deletions) / total words in the reference transcript. A WER of 0.05 means 5% of words contain errors. It's most useful for benchmarking AI-generated transcripts that rely on speech recognition and natural language processing before you move to human review. WER won't catch contextual errors or missed non-verbal cues, so it works best as a first-pass filter for accurate transcription rather than a complete validation method. You still need a full audio-text comparison to catch what WER misses.
How accurate is AI transcription for qualitative research?
Most transcription software powered by speech recognition delivers 85-95% accuracy on clean audio recordings. That sounds high, but in a 10,000-word transcript, even 5% errors means 500 words are wrong, and some of those errors will land in analytically critical passages. For qualitative research, where the transcribed data is the primary dataset, that margin isn't acceptable without human review. HappyScribe addresses this by letting you run AI transcription for a fast first draft and then escalate to human proofreading that brings accuracy to 99%.
What is the difference between verbatim and intelligent verbatim transcription?
Verbatim transcription captures everything: filler words, false starts, repetitions, pauses, laughter, and non-verbal communication. Intelligent verbatim cleans up the text by removing filler and repetition while preserving the meaning of what was said. The right choice depends on your qualitative analysis method.
If you're doing thematic analysis where you're looking for common themes and patterns across participants, intelligent verbatim is usually sufficient because the data analysis focuses on meaning rather than delivery. And if your research depends on how something was said, such as conversation analysis or discourse analysis, verbatim is the only option because removing filler strips the data of the details you need to analyze.
How long does it take to validate a qualitative research transcript?
A full audio-text comparison of a single 60-minute interview typically takes 2-3 hours if you're reviewing carefully. The exact timeline depends on recording length, audio quality, and the number of validation steps in your protocol. Add member checking, peer debriefing, and consistency checks across your dataset, and you're looking at significantly more time per transcript.
For projects with large volumes of interview transcripts or video data, the validation phase can take as long as the data collection phase itself. Using AI transcription for the first draft cuts the initial conversion of spoken words to text down to minutes, which gives you more time for the validation that protects your research results from data loss and inaccuracy.
What should a transcription protocol include for qualitative research?
Your protocol should define notation conventions before anyone on the team starts transcribing. At a minimum, document how you'll mark pauses, overlapping speech from multiple speakers, inaudible segments, and emotional tone. Specify whether you're using verbatim or intelligent verbatim, and explain why that choice fits your qualitative analysis approach.
Include rules for speaker labeling, timestamp intervals, and how to handle sensitive content where ethical considerations apply. If your institution or regulatory bodies require specific data handling procedures for audio recordings, document those in the protocol too.
A strong protocol keeps data collected across all the interviews consistent, which makes your thematic analysis more reliable and your audit trail easier to defend.

Biplab Mazumder
Biplab is a content marketer and writer who helps high-growth brands scale content visibility across AI search channels. His works have been published in HubSpot, Freshworks, Atlassian, SurferSEO, etc. When he's not planning content strategy, he's testing AI content workflows and use cases.





