![Jak analizować transkrypcje wywiadów w badaniach jakościowych? [Przewodnik 2026]](/sanity-images/ejgwz1gl/redesign/c24a436b1e0b9c35b4a6af6af8c6ee860160aca5-1536x1024.png?auto=format&w=1536.0&rect=0,128,1536,768&h=768)
Aby przeanalizować transkrypcje wywiadów w badaniach jakościowych, należy przejść przez sześcioetapowy proces: zapoznać się z danymi, wygenerować wstępne kody poprzez oznaczanie istotnych segmentów, pogrupować kody w potencjalne tematy, zweryfikować tematy w zestawieniu z danymi, zdefiniować i nazwać każdy temat oraz opracować wyniki wraz z cytatami na poparcie wniosków.
Wybrana metoda analityczna (analiza tematyczna, teoria ugruntowana lub inne podejście) określi sposób realizacji każdego z etapów.
Zanim zaczniesz: przygotuj transkrypcje do analizy
Masz już swoje transkrypcje. Przed uruchomieniem oprogramowania do kodowania lub sięgnięciem po zakreślacz sprawdź, czy same transkrypcje są sformatowane pod kątem sprawnej analizy.
Zwróć uwagę na te cztery elementy:
Identyfikacja mówców
Każda wypowiedź powinna być przypisana do oznaczonego mówcy (Prowadzący wywiad, P1, P2 i tak dalej). Bez wyraźnej identyfikacji mówców śledzenie, kto co powiedział, w 15 czy 20 transkrypcjach staje się żmudne i podatne na błędy.
Znaczniki czasu
Umieszczone w regularnych odstępach lub w kluczowych momentach znaczniki czasu pozwalają wrócić do źródłowego nagrania, gdy zakodowany fragment jest niejednoznaczny. Ton, akcent i pauzy mogą zmienić sposób interpretacji segmentu, a znaczniki czasu ułatwiają odnalezienie właściwego momentu w nagraniu.
Czysty tekst z możliwością wyszukiwania
Potrzebujesz tekstu cyfrowego, który można przeszukiwać za pomocą Ctrl+F, zakreślać i importować do oprogramowania do analizy danych jakościowych. Zeskanowane obrazy odręcznych notatek znacznie Cię spowolnią.
Spójny podział na akapity
Akapity powinny być dzielone w naturalnych miejscach zmiany mówcy lub zmiany tematu, a nie tworzyć transkrypcje będące ścianą tekstu, ciągnące się przez całe strony bez żadnej przerwy.
Jeśli Twoje transkrypcje nie mają jeszcze takiej postaci, zapoznaj się z naszymi przewodnikami na temat transkrypcji w badaniach jakościowych oraz rodzajów transkrypcji, aby wybrać odpowiednie podejście do transkrypcji dla swojego badania.
Uzyskanie transkrypcji gotowych do analizy nie musi oznaczać godzin ręcznego formatowania. HappyScribe automatycznie generuje transkrypcje z identyfikacją mówców, znacznikami czasu i czytelnym podziałem na akapity, niezależnie od tego, czy korzystasz ze ścieżki transkrypcji AI (dostarczanej w kilka minut), czy przesyłasz nagrania do profesjonalnych korektorów w celu uzyskania 99% dokładności (dostarczanej w ciągu 24 godzin).
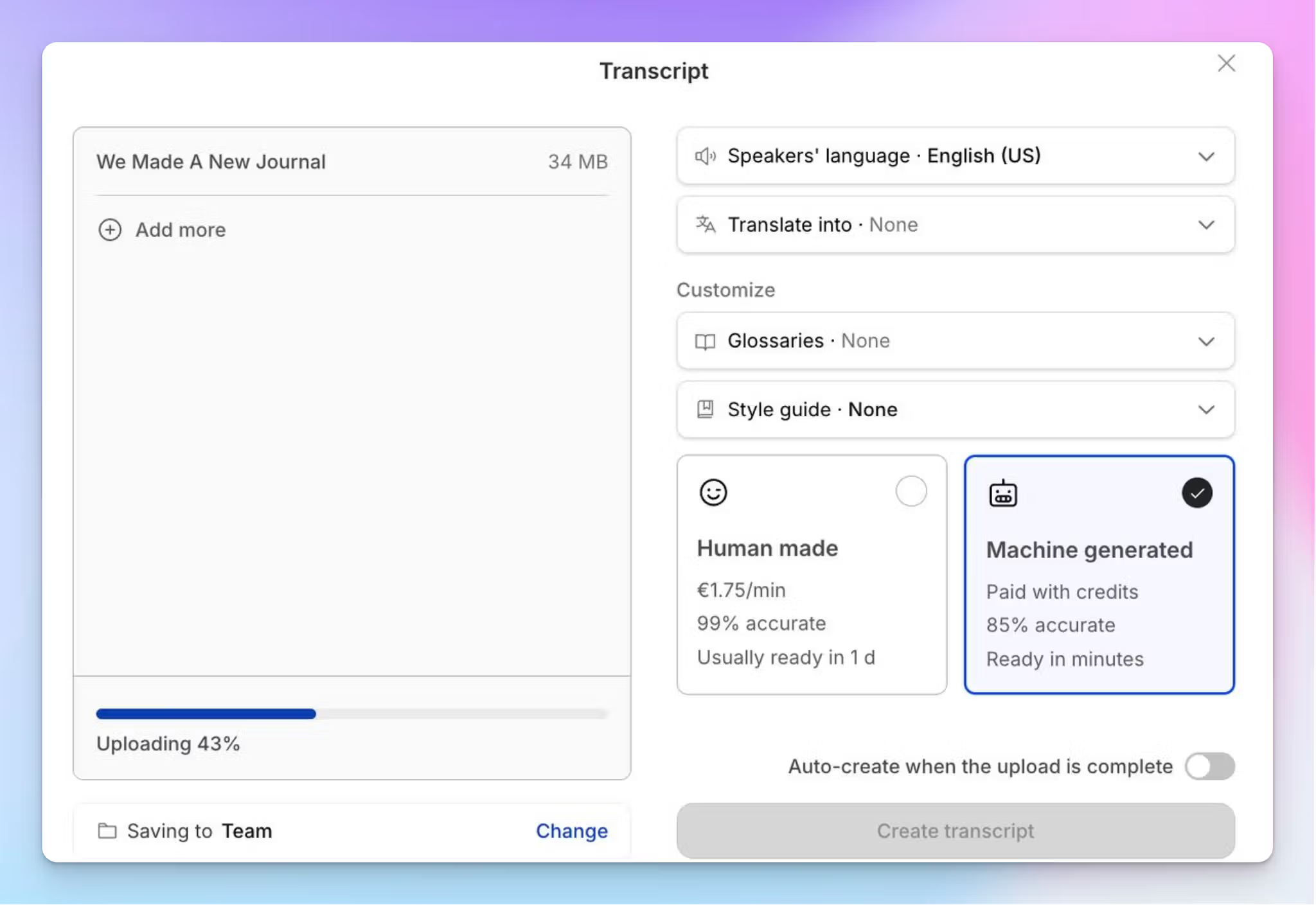
Wbudowany edytor HappyScribe synchronizuje odtwarzanie dźwięku z transkrypcją, dzięki czemu możesz zweryfikować dowolny fragment z oryginalnym nagraniem bez przełączania się między aplikacjami. Jest to pomocne w analizie, ponieważ sprawdzanie tonu i akcentu na etapie zapoznawania się z danymi jest znacznie łatwiejsze, gdy możesz kliknąć zdanie i natychmiast usłyszeć odpowiadający mu fragment dźwięku.
Dzięki obsłudze ponad 150 języków HappyScribe jest szczególnie przydatny w badaniach wielojęzycznych lub międzykulturowych, w których wywiady mogą być prowadzone w jednym języku, a analizowane w innym.
Co więcej, AI Chat od HappyScribe pomaga wydobyć powracające tematy, wyciągnąć dokładne cytaty, porównać, jak różni uczestnicy odpowiadali na ten sam temat, oraz dostrzec wzorce w dziesiątkach wywiadów bez ręcznego przekopywania się przez transkrypcje.
Po sfinalizowaniu transkrypcji wyeksportuj je w formatach TXT, DOCX lub SRT, gotowe do zaimportowania do NVivo, ATLAS.ti, MAXQDA lub dowolnego innego narzędzia QDA.
Etapy analizy transkrypcji wywiadów w badaniach jakościowych
Etap 1: zapoznaj się z danymi
Przeczytaj każdą transkrypcję co najmniej dwukrotnie, zanim zaczniesz kodować. Przy pierwszym czytaniu po prostu czytaj. Nie zakreślaj, nie oznaczaj, nie koduj. Pozwól, by dane na Ciebie podziałały. Prowadź osobny notatnik lub plik z notatkami, w którym zapiszesz pierwsze wrażenia: co Cię zaskoczyło, co powtarzało się wielokrotnie, co wydało się istotne w kontekście Twoich pytań badawczych.
Przy drugim czytaniu zacznij zaznaczać fragmenty, które wydają się istotne. Podkreślaj, pogrubiaj lub korzystaj z funkcji adnotacji w swoim oprogramowaniu, ale powstrzymaj się jeszcze od przypisywania kodów. Wciąż wyrabiasz sobie wyczucie ogólnego kształtu zbioru danych.
Jeśli nie transkrybowałeś wywiadów samodzielnie, odsłuchaj fragmenty nagrania równolegle z transkrypcją. Tekst pisany pozbawia wypowiedź tonu, wahania i akcentu, co może zmienić sposób odczytania danego fragmentu. Jest to szczególnie ważne w przypadku wywiadów dotyczących tematów drażliwych lub naładowanych emocjonalnie.
Braun and Clarke (2006), których sześciofazowy framework analizy tematycznej pozostaje najczęściej cytowanym podejściem w badaniach jakościowych, opisują to jako fazę zapoznawania się z danymi. Badanie podkreśla, że powinno to być "aktywne" czytanie, podczas którego poszukujesz znaczeń i wzorców, zamiast biernie przyswajać treść.
📚 Przeczytaj również:
Etap 2: wygeneruj wstępne kody
Kodowanie to moment, w którym zaczyna się praca analityczna. Kod to krótka etykieta (słowo lub krótkie wyrażenie) przypisana do segmentu tekstu transkrypcji, która ujmuje, czego ten segment dotyczy. Kody są elementami konstrukcyjnymi analizy jakościowej. Wszystko, co następuje później (tematy, wyniki i interpretacja), opiera się na jakości Twoich kodów.
Dwa podejścia do kodowania:
a. Indukcyjne (kierowane danymi): Kody wyłaniają się z samych danych. Czytasz transkrypcję i oznaczasz to, co widzisz, bez z góry ustalonej listy. To standardowe podejście w badaniach eksploracyjnych, analizie tematycznej i teorii ugruntowanej.
b. Dedukcyjne (kierowane teorią): Zaczynasz od z góry zdefiniowanego zestawu kodów opartego na Twoich pytaniach badawczych, ramach teoretycznych lub istniejącej literaturze. Następnie szukasz w danych dowodów na te kody. Jest to częste w badaniach testujących lub rozwijających ugruntowane teorie. Wiele badań korzysta z podejścia hybrydowego: zaczyna od frameworku dedukcyjnego, a następnie dodaje kody indukcyjne dla wszystkiego, czego framework nie obejmuje.
Typowe rodzaje kodowania:
- Kody opisowe oznaczają temat fragmentu: "obciążenie pracą", "dynamika zespołu", "proces wdrożenia"
- Kody in vivo wykorzystują własne słowa uczestnika. Uczestnik mówi "Czułem się niewidzialny na tych spotkaniach", a "niewidzialny" staje się kodem
- Kody procesowe ujmują działania lub zmiany opisywane przez uczestników: "narastające skargi", "przystosowywanie się do pracy zdalnej"
Jak wygląda kodowanie w praktyce:
P4: "Wciąż poruszałem to z moim przełożonym, ale nic się nie zmieniło. Po jakimś czasie po prostu przestałem o tym wspominać. Po co?" [kody: nierozwiązany feedback, brak zaangażowania, poczucie bezsensu]
Koduj hojnie przy pierwszym czytaniu. Łatwiej później scalić lub odrzucić kody, niż ponownie czytać 20 transkrypcji w poszukiwaniu rzeczy, które za pierwszym razem przeoczyłeś. Korzystaj z księgi kodów (bieżącej listy kodów wraz z krótkimi definicjami), aby zachować spójność kodowania w różnych transkrypcjach i między badaczami.
Więcej o tworzeniu systemu tagowania już na etapie samej transkrypcji znajdziesz w naszym przewodniku na temat wykorzystania tematów i tagów podczas transkrybowania wywiadów w badaniach jakościowych.
Etap 3: szukaj tematów
Temat to wzorzec znaczeniowy, który ujmuje coś istotnego w danych w odniesieniu do Twojego pytania badawczego. Tematy buduje się z kodów, ale funkcjonują one na wyższym poziomie abstrakcji.
Rozłóż wszystkie swoje kody (w arkuszu kalkulacyjnym lub w menedżerze kodów Twojego oprogramowania QDA) i poszukaj skupisk. Które kody zdają się do siebie pasować? Które kody pojawiają się u wielu uczestników?
Pogrupuj powiązane kody pod etykietami potencjalnych tematów. Na przykład kody takie jak "nierozwiązany feedback", "zmieniające się terminy" i "brak jasnych oczekiwań" mogą zostać zgrupowane pod potencjalnym tematem "niejednoznaczność w definicji roli".
Nie każdy kod będzie pasował do tematu. Niektóre kody mogą pozostać osobno, niektóre mogą być zbyt rzadkie, aby utrzymać temat, a niektóre mogą ostatecznie zostać odrzucone. To normalne i oczekiwane. Na tym etapie tematy są wstępne. Zostaną przetestowane i dopracowane w kolejnym kroku.
Etap 4: zweryfikuj i dopracuj tematy
Ten etap ma dwa poziomy.
a. Sprawdź tematy w zestawieniu z zakodowanymi fragmentami: Przeczytaj wszystkie segmenty zgrupowane pod każdym potencjalnym tematem. Czy są ze sobą spójne? Czy etykieta tematu trafnie je opisuje?
Jeśli temat wydaje się zbyt szeroki, być może trzeba go podzielić na dwa. Jeśli dwa tematy mocno się pokrywają, być może trzeba je scalić. Jeśli temat zawiera segmenty, które w istocie do siebie nie pasują, przypisz te segmenty w innym miejscu.
b. Sprawdź tematy w zestawieniu z całym zbiorem danych: Wróć do swoich transkrypcji, a przynajmniej do kluczowych fragmentów, i przeczytaj je, mając na uwadze swoją strukturę tematów. Upewnij się, że tematy odzwierciedlają dane jako całość, a nie tylko te fragmenty, które akurat zakodowałeś.
Szukaj zwłaszcza danych, które zaprzeczają Twoim tematom. Zmierzenie się z przypadkami negatywnymi lub odbiegającymi od reszty wzmacnia Twoją analizę.
Jeśli na tym etapie tematy się rozpadają lub znacznie mnożą, jest to oznaka, że analiza działa, a nie że coś poszło nie tak. Analiza jakościowa jest iteracyjna. Spodziewaj się, że ten etap będziesz powtarzać więcej niż raz.
Etap 5: zdefiniuj i nazwij swoje tematy
Dla każdego tematu napisz krótką definicję (dwa do trzech zdań), która ujmuje, czego temat dotyczy, jaki aspekt danych reprezentuje i jak łączy się z Twoim pytaniem badawczym.
Następnie nadaj każdemu tematowi zwięzłą, konkretną nazwę. "Komunikacja" jest zbyt ogólnikowa. "Zaburzenia w komunikacji oddolnej podczas zmiany organizacyjnej" ujmuje temat bez potrzeby dalszych wyjaśnień.
Ten etap często wykonuje się pospiesznie, ale to on decyduje o tym, jak klarownie czyta się sekcja z wynikami. Jeśli nie potrafisz napisać zwięzłej, dwuzdaniowej definicji tematu, prawdopodobnie temat nie jest jeszcze na tyle dobrze zdefiniowany, by o nim pisać.
Etap 6: opracuj swoje wyniki
Zbuduj sekcję z wynikami wokół swoich tematów, ujmując każdy temat jako podtytuł lub odrębną sekcję.
Dla każdego tematu przedstaw argument (co dany temat oznacza i dlaczego ma znaczenie), poprzyj go danymi (bezpośrednie cytaty z transkrypcji, z etykietami uczestników i z kontekstem wystarczającym, by czytelnik zrozumiał cytat) oraz powiąż go ze swoimi pytaniami badawczymi lub szerszą literaturą.
Korzystaj z cytatów celowo. Krótki, dobrze dobrany cytat ilustrujący konkretny punkt jest skuteczniejszy niż długi cytat blokowy, który czytelnik musi sam zinterpretować. Wprowadzaj każdy cytat kontekstem ("Zapytany o wsparcie ze strony kierownictwa, P4 opisał wzorzec braku zaangażowania:") i opatrz go swoją interpretacją tego, co cytat pokazuje.
Odróżniaj opis (to, co powiedzieli uczestnicy) od interpretacji (to, co oznacza w odniesieniu do Twojego pytania badawczego). Oba elementy są niezbędne. Opis bez interpretacji to streszczenie, a nie analiza.
Jak wybrać odpowiednią metodę analityczną
Nie każda analiza jakościowa przebiega według opisanego powyżej sześcioetapowego procesu tematycznego. Etapy mają szerokie zastosowanie, ale różne metody ważą je inaczej i dodają własną logikę. Oto krótkie wprowadzenie:
| Metoda | Najlepsza do | Główny proces |
|---|---|---|
| Analiza tematyczna (Braun & Clarke, 2006) | Identyfikowanie wzorców w obrębie zbioru danych; elastyczna, sprawdza się przy większości projektów jakościowych | Sześć faz: zapoznanie się, kodowanie, poszukiwanie tematów, weryfikacja, definiowanie, opracowanie |
| Teoria ugruntowana | Budowanie teorii na podstawie danych, gdy nie istnieje silna wcześniejsza teoria | Kodowanie otwarte, osiowe i selektywne; stałe porównywanie; dobór teoretyczny aż do nasycenia |
| Interpretacyjna analiza fenomenologiczna (IPA) | Zrozumienie przeżywanego doświadczenia niewielkiej liczby uczestników (zwykle od 3 do 10) | Analiza przypadek po przypadku, następnie wzorce między przypadkami; nacisk na to, jak uczestnicy nadają sens doświadczeniu |
| Analiza ramowa | Badania stosowane lub badania nad politykami z konkretnymi pytaniami do udzielenia odpowiedzi | Z góry zdefiniowany framework; systematyczne nanoszenie danych na macierz |
| Analiza narracyjna | Zrozumienie, jak ludzie konstruują znaczenie poprzez opowiadanie historii | Nacisk na fabułę, sekwencję, postacie i punkty zwrotne w obrębie poszczególnych relacji |
| Analiza dyskursu | Badanie, jak język konstruuje rzeczywistość społeczną | Nacisk na użycie języka, dynamikę władzy, pozycjonowanie i strategie retoryczne |
Jeśli nie masz pewności, która metoda pasuje do Twojego badania, zacznij od swojego pytania badawczego. Pytania o wzorce i doświadczenia w obrębie grupy uczestników skłaniają się ku analizie tematycznej, natomiast pytania o to, jak poszczególne osoby nadają sens konkretnemu doświadczeniu, skłaniają się ku IPA.
📚 Przeczytaj również:
Ile kosztuje transkrypcja wywiadów?
Narzędzia do kodowania i analizy transkrypcji
- Oprogramowanie do analizy danych jakościowych (QDA): NVivo, ATLAS.ti, MAXQDA i Dedoose to jedne z popularnych opcji. Pozwalają importować transkrypcje, stosować kody, grupować kody w tematy, uruchamiać zapytania (częstość kodów, współwystępowanie kodów) i wizualizować relacje
- Lekkie alternatywy: W przypadku mniejszych badań (poniżej 10 transkrypcji) dobrze sprawdza się kodowanie za pomocą arkusza kalkulacyjnego, edytora tekstu z komentarzami lub wydrukowanych transkrypcji z kolorowymi zakreślaczami. Metoda ma większe znaczenie niż narzędzie. Drogie oprogramowanie samo z siebie nie zapewnia lepszej analizy
- Kodowanie wspomagane przez AI: Narzędzia AI potrafią już generować wstępne księgi kodów, sugerować kody dla segmentów transkrypcji i sygnalizować potencjalne tematy. Badanie PMC z 2025 roku na temat AI w badaniach jakościowych opisało rosnącą rolę AI w generowaniu ksiąg kodów, automatycznym kodowaniu i identyfikacji tematów, podkreślając zarazem, że badacz musi przejrzeć, dopracować i zinterpretować cały wynik wygenerowany przez AI
Konsensus: AI przyspiesza mechaniczne części kodowania, ale nie może zastąpić osądu interpretacyjnego, który nadaje badaniom jakościowym ich wartość.
Połącz transkrypcję z analizą za pomocą HappyScribe
Niezależnie od tego, jakiego narzędzia używasz do kodowania, jakość Twoich transkrypcji bezpośrednio wpływa na to, jak szybko możesz przejść przez analizę.
Na przykład transkrypcje bez identyfikacji mówców zmuszają do ponownego odsłuchiwania nagrania, aby ustalić, kto co powiedział. Transkrypcje bez znaczników czasu uniemożliwiają wyrywkowe zweryfikowanie cytatu z nagraniem bez przewijania całego pliku. Formatowanie w postaci ściany tekstu spowalnia wizualne przeglądanie i utrudnia wyodrębnianie segmentów nadających się do zakodowania.
To właśnie tutaj etap transkrypcji i etap analizy się łączą i gdzie HappyScribe wnosi największą wartość do przepływów pracy w badaniach. Każda transkrypcja jest dostarczana z automatyczną identyfikacją mówców, akapitami opatrzonymi znacznikami czasu oraz uporządkowanym formatowaniem, które oprogramowanie QDA potrafi odczytać podczas importu.
W przypadku zespołów badawczych zarządzających dziesiątkami wywiadów między wieloma osobami kodującymi spójność formatowania zapewnia, że wszyscy pracują na transkrypcjach o identycznej strukturze.
Najczęściej zadawane pytania o analizę transkrypcji wywiadów w badaniach jakościowych
Ilu transkrypcji wywiadów potrzebuję do analizy tematycznej?
Nie ma uniwersalnej liczby. W przypadku wywiadów jakościowych opartych na pogłębionych rozmowach od 12 do 25 uczestników to wartość typowa dla większości organizacji. Zasadą przewodnią jest nasycenie: gdy nowe kody i wspólne tematy przestają wyłaniać się ze zbioru danych. Cele Twojego badania, temat badawczy oraz zakres scenariusza wywiadu wpływają na właściwą liczbę. W przypadku badań IPA skupionych na głębszym zrozumieniu indywidualnego doświadczenia typowe jest od 3 do 10 uczestników.
Jaka jest różnica między kodem a tematem w analizie danych jakościowych?
Kod to krótka etykieta, którą przypisujesz do konkretnych segmentów surowych danych podczas systematycznego kodowania. Temat grupuje zakodowane dane w szerszy wzorzec znaczeniowy w odniesieniu do Twoich pytań badawczych. Kody są elementami konstrukcyjnymi; tematy są strukturami z nich zbudowanymi. Podczas wstępnego kodowania oznaczasz fragmenty, a następnie szukasz wspólnych tematów, aby zacząć tworzyć wyniki i wydobywać kluczowe wnioski.
Czy powinienem stosować kodowanie indukcyjne czy dedukcyjne?
Badania eksploracyjne wymagają kodowania indukcyjnego, w którym nowe kody wyłaniają się z zebranych danych. Badania z ramami teoretycznymi wymagają kodowania dedukcyjnego z użyciem z góry zdefiniowanych kodów. Wielu badaczy jakościowych stosuje oba. Niezależnie od tego, jaką metodę kodowania wybierzesz, pisanie notatek pomaga uchwycić głębsze znaczenia i istotne wnioski. Celem jest przejście od słów wypowiedzianych przez uczestników do znaczących wniosków, które wspierają szerszą perspektywę na Twój temat badawczy.
Czy narzędzia AI mogą pomóc mi analizować dane jakościowe z transkrypcji wywiadów?
Analiza AI może pomóc szybciej analizować dane jakościowe poprzez generowanie chmur słów, sygnalizowanie kluczowych tematów i wydobywanie praktycznych wniosków z wielu źródeł, w tym z grup fokusowych i odpowiedzi ankietowych. AI Chat od HappyScribe pozwala porównywać odpowiedzi uczestników i wyciągać dokładne cytaty na tej samej platformie, na której znajdują się Twoje pliki transkrypcji. Zawsze jednak weryfikuj tematy i przeglądaj przeanalizowane dane. AI przyspiesza mechaniczne części procesu badawczego, ale nie może zastąpić osądu interpretacyjnego.
Jak zapewnić rzetelność między osobami kodującymi podczas analizy transkrypcji wywiadów?
Niech każdy członek zespołu badawczego niezależnie zakoduje podzbiór danych jakościowych (zwykle 10-20%), porównaj wyniki i rozstrzygnij rozbieżności. Ten kluczowy krok zapobiega typowym błędom w dużych projektach. Ustal wspólną księgę kodów, zanim rozpocznie się pierwsza runda analizy danych z wywiadów. Oprogramowanie analityczne takie jak NVivo pomaga zarządzać zakodowanymi danymi w całym zbiorze danych. Podaj poziomy zgodności w swojej metodologii.

Rodoshi Das
Rodoshi pomaga markom SaaS rozwijać się dzięki treściom, które konwertują i wspinają się w wynikach wyszukiwania i modelach LLM. Spędza dni na testowaniu narzędzi i zamienia swoje doświadczenia w ciekawe narracje, pomagając użytkownikom podejmować świadome decyzje zakupowe. Po pracy zamienia dashboardy na kryminały i terapię ogrodową.