![How to Analyze Interview Transcripts in Qualitative Research? [2026 Guide]](/sanity-images/ejgwz1gl/redesign/c24a436b1e0b9c35b4a6af6af8c6ee860160aca5-1536x1024.png?auto=format&w=1536.0&rect=0,128,1536,768&h=768)
To analyze interview transcripts in qualitative research, follow a six-step process: familiarize yourself with the data, generate initial codes by labeling meaningful segments, group codes into candidate themes, review themes against the data, define and name each theme, and write up findings with supporting quotes.
The specific analytical method you choose (thematic analysis, grounded theory, or another approach) will shape how you execute each step.
Before you start: Get your transcripts analysis-ready
You have your transcripts. Before opening your coding software or reaching for a highlighter, check that the transcripts themselves are formatted for efficient analysis.
Look for these four things:
Speaker labels
Every utterance should be attributed to a labeled speaker (Interviewer, P1, P2, and so on). Without clear speaker labels, tracking which participant said what across 15 or 20 transcripts becomes tedious and error-prone.
Timestamps
Placed at regular intervals or at key moments, timestamps let you jump back to the source audio when a coded passage is ambiguous. Tone, emphasis, and pauses can change how a segment should be interpreted, and timestamps make it easy to locate the right moment in the recording.
Clean, searchable text
You need digital text that you can search with Ctrl+F, highlight, and import into qualitative data analysis software. Scanned images of handwritten notes will significantly slow you down.
Consistent paragraph breaks
Paragraphs should be broken at natural speaker turns or topic shifts, not wall-of-text transcripts that run for pages without a break.
If your transcripts are not yet in this shape, see our guides on transcription in qualitative research and types of transcription for guidance on choosing the right transcription approach for your study.
Getting analysis-ready transcripts does not have to mean hours of manual formatting. HappyScribe generates transcripts with speaker labels, timestamps, and clean paragraph breaks automatically, whether you use the AI transcription path (delivered in minutes) or send recordings to human proofreaders for 99% accuracy (delivered within 24 hours).
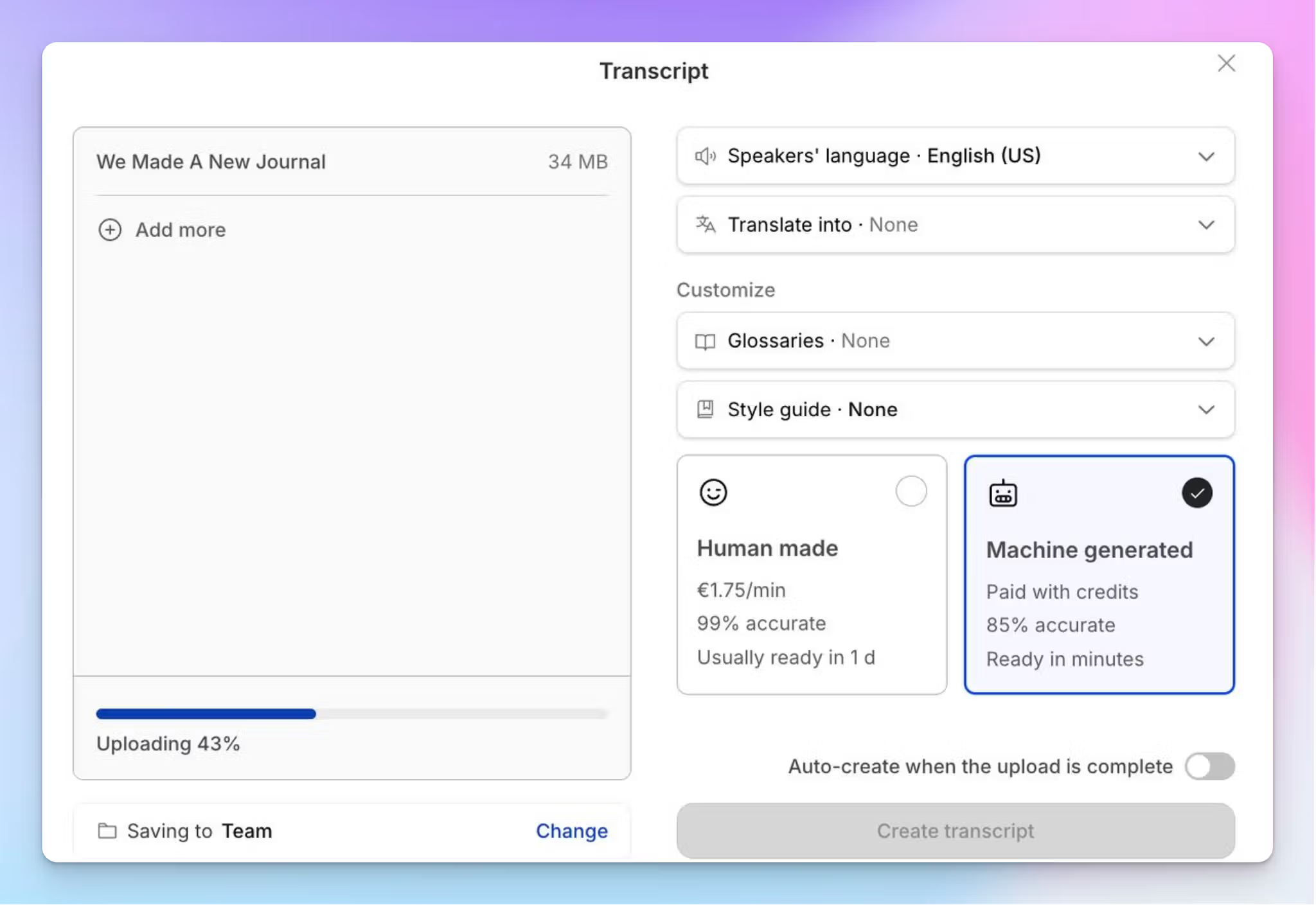
HappyScribe’s built-in editor syncs audio playback with the transcript, so you can verify any passage against the original recording without switching between apps. This is helpful for analysis because checking tone and emphasis during familiarization is far easier when you can click a sentence and hear the corresponding audio instantly.
With support for over 150 languages, HappyScribe is particularly useful for multilingual or cross-cultural research where interviews may be conducted in one language and analyzed in another.
On top of that, HappyScribe’s AI Chat helps you surface recurring themes, pull exact quotes, compare how different participants responded to the same topic, and spot patterns across dozens of interviews without manually digging through transcripts.
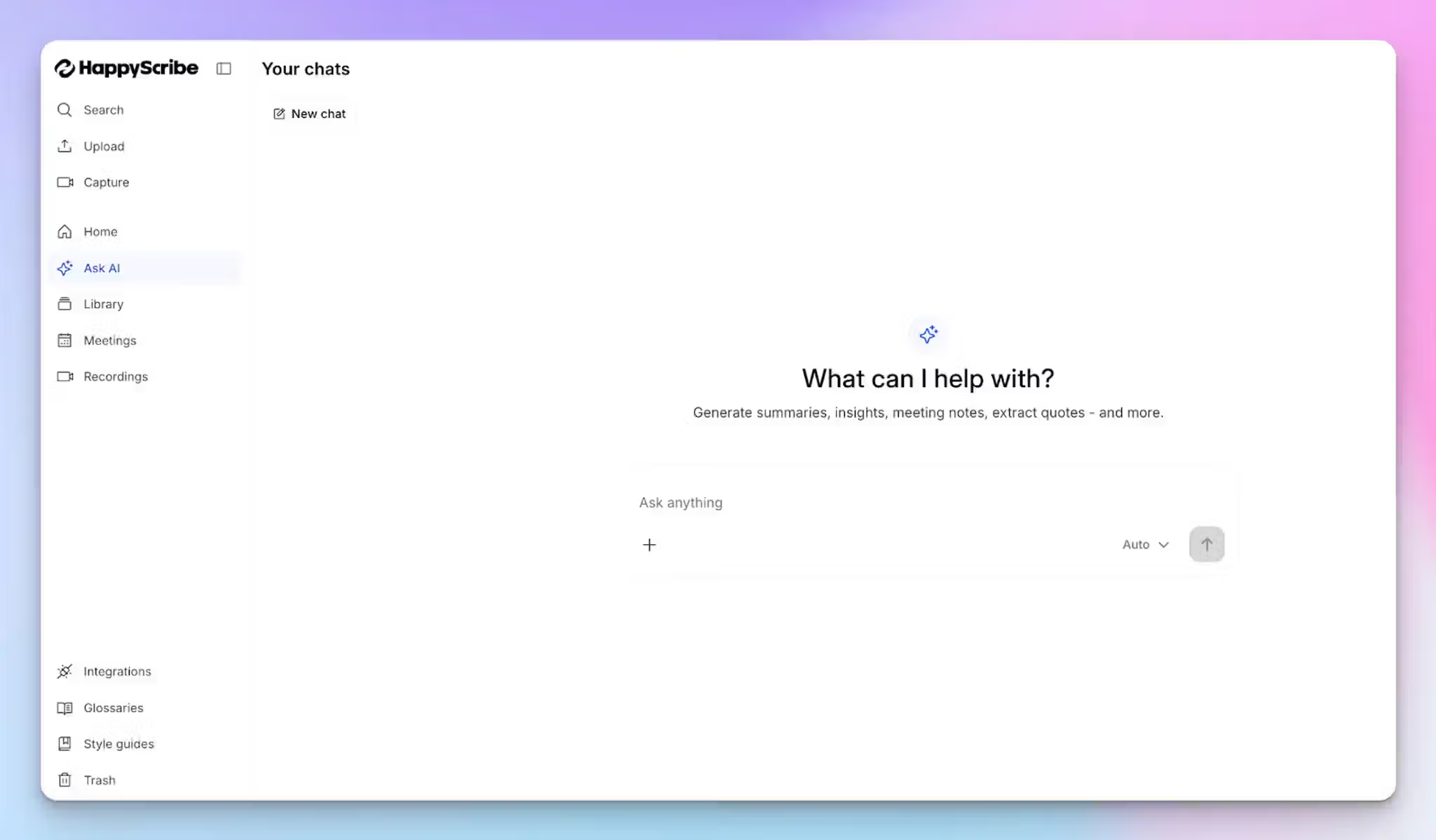
Once your transcripts are finalized, export them in TXT, DOCX, or SRT formats ready for import into NVivo, ATLAS.ti, MAXQDA, or any other QDA tool.
Steps to analyze interview transcripts in qualitative research
Step 1: Familiarize yourself with the data
Read every transcript at least twice before you start coding. On the first pass, just read. Do not highlight, do not label, do not code. Let the data wash over you. Keep a separate notebook or memo file where you jot down initial impressions: what surprised you, what came up repeatedly, what felt significant in relation to your research questions.
On the second pass, begin flagging passages that seem meaningful. Underline, bold, or use your software's annotation function, but resist the urge to assign codes yet. You are still getting a feel for the overall shape of the dataset.
If you did not transcribe the interviews yourself, listen to sections of the audio alongside the transcript. Written text strips away tone, hesitation, and emphasis, which can change how a passage is read. It’s especially important for interviews that touch on sensitive or emotionally charged topics.
Braun and Clarke (2006), whose six-phase framework for thematic analysis remains the most widely cited approach in qualitative research, describe this as the familiarization phase. The study emphasizes that it should be "active" reading, where you search for meanings and patterns rather than passively absorb content.
📚 Also read:
Step 2: Generate initial codes
Coding is where the analytical work begins. A code is a short label (a word or brief phrase) applied to a segment of transcript text that captures what that segment is about. Codes are the building blocks of qualitative analysis. Everything that follows, themes, findings, and interpretation, is built on the quality of your codes.
Two approaches to coding:
a. Inductive (data-driven): Codes emerge from the data itself. You read the transcript and label what you see, without a predetermined list. This is the standard approach for exploratory studies, thematic analysis, and grounded theory.
b. Deductive (theory-driven): You start with a predefined set of codes based on your research questions, theoretical framework, or existing literature. You then look for evidence of those codes in the data. It’s common in studies testing or extending established theories. Many studies use a hybrid: start with a deductive framework, then add inductive codes for anything the framework does not capture.
Common coding types:
- Descriptive codes label the topic of a passage: "workload," "team dynamics," "onboarding process"
- In vivo codes use the participant's own words. A participant says "I felt invisible in those meetings," and "invisible" becomes a code
- Process codes capture actions or changes described by participants: "escalating complaints," "adapting to remote work"
What coding looks like in practice:
P4: "I kept raising it with my manager, but nothing changed. After a while I just stopped bringing it up. What's the point?" [codes: unresolved feedback, disengagement, perceived futility]
Code generously in the first pass. It is easier to merge or discard codes later than to re-read 20 transcripts for things you missed the first time. Use a codebook (a running list of your codes with short definitions) to keep coding consistent across transcripts and across researchers.
For more on developing your tagging system during transcription itself, see our guide on using themes and tags when transcribing qualitative research interviews.
Step 3: Search for themes
A theme is a pattern of meaning that captures something significant about the data in relation to your research question. Themes are built from codes, but they operate at a higher level of abstraction.
Lay out all your codes (in a spreadsheet or in your QDA software's code manager) and look for clusters. Which codes seem to go together? Which codes appear across multiple participants?
Group related codes under candidate theme labels. For example, codes like "unresolved feedback," "shifting deadlines," and "no clear expectations" might cluster under a candidate theme of "ambiguity in role definition."
Not every code will fit a theme. Some codes may stand alone, some may be too infrequent to support a theme, and some may end up discarded. That is normal and expected. At this stage, themes are provisional. They will be tested and refined in the next step.
Step 4: Review and refine themes
This step has two levels.
a. Check themes against the coded extracts: Read all the segments you grouped under each candidate theme. Do they cohere? Does the theme label accurately describe them?
If a theme feels too broad, it may need to be split into two. If two themes overlap heavily, they may need to be merged. If a theme contains segments that do not actually fit together, reassign those segments elsewhere.
b. Check themes against the full dataset: Go back to your transcripts, or at least key sections, and read them with your theme structure in mind. Confirm that the themes reflect the data as a whole, not just the passages you happened to code.
Look specifically for data that contradicts your themes. Engaging with negative or deviant cases strengthens your analysis.
If themes collapse or multiply significantly at this stage, that is a sign the analysis is working, not a sign something has gone wrong. Qualitative analysis is iterative. Expect to cycle through this step more than once.
Step 5: Define and name your themes
For each theme, write a brief definition (two to three sentences) that captures what the theme is about, what aspect of the data it represents, and how it connects to your research question.
Then give each theme a concise, specific name. "Communication" is too vague. "Breakdowns in upward communication during organizational change" captures the theme without further explanation.
This step often gets rushed, but it determines how clearly your findings section reads. If you cannot write a crisp two-sentence definition of a theme, the theme is probably not yet well-defined enough to write about.
Step 6: Write up your findings
Structure your findings section around your themes, with each theme as a subheading or distinct section.
For each theme, present the argument (what the theme means and why it matters), support it with data (direct quotes from the transcripts, with participant labels and enough context for the reader to understand the quote), and connect it to your research questions or the broader literature.
Use quotes purposefully. A short, well-chosen quote that illustrates a specific point is more effective than a long block quote that the reader has to interpret on their own. Introduce each quote with context ("When asked about managerial support, P4 described a pattern of disengagement:") and follow it with your interpretation of what the quote demonstrates.
Distinguish between description (what participants said) and interpretation (what it means in relation to your research question). Both are necessary. Description without interpretation is a summary, not an analysis.
How to choose the right analytical method
Not all qualitative analysis follows the six-step thematic process described above. The steps are broadly applicable, but different methods weigh them differently and add their own logic. Here is a brief orientation:
| Method | Best for | Core process |
|---|---|---|
| Thematic analysis (Braun & Clarke, 2006) | Identifying patterns across a dataset; flexible, works with most qualitative designs | Six phases: familiarize, code, search for themes, review, define, write up |
| Grounded theory | Building theory from data when no strong prior theory exists | Open, axial, and selective coding; constant comparison; theoretical sampling until saturation |
| Interpretive phenomenological analysis (IPA) | Understanding lived experience of a small number of participants (generally 3 to 10) | Case-by-case analysis, then cross-case patterns; focus on how participants make sense of experience |
| Framework analysis | Applied or policy research with specific questions to answer | Predefined framework; systematic charting of data into a matrix |
| Narrative analysis | Understanding how people construct meaning through storytelling | Focus on plot, sequencing, characters, and turning points within individual accounts |
| Discourse analysis | Examining how language constructs social reality | Focus on language use, power dynamics, positioning, and rhetorical strategies |
If you are unsure which method fits your study, start with your research question. Questions about patterns and experiences across participants lean toward thematic analysis, whereas questions about how individuals make sense of a specific experience lean toward IPA.
📚 Also read:
Tools for coding and analyzing transcripts
- Qualitative data analysis (QDA) software: NVivo, ATLAS.ti, MAXQDA, and Dedoose are some common options. They let you import transcripts, apply codes, group codes into themes, run queries (code frequency, code co-occurrence), and visualize relationships
- Lightweight alternatives: For smaller studies (under 10 transcripts), coding with a spreadsheet, a word processor with comments, or printed transcripts with colored highlighters works well. The method matters more than the tool. Expensive software does not produce better analysis by default
- AI-assisted coding: AI tools can now generate initial codebooks, suggest codes for transcript segments, and flag potential themes. A 2025 PMC study on AI in qualitative research described AI's expanding role in codebook generation, automated coding, and theme identification, while emphasizing that the researcher must review, refine, and interpret all AI-generated output
The consensus: AI accelerates the mechanical parts of coding but cannot replace the interpretive judgment that gives qualitative research its value.
Connect transcription with analysis using HappyScribe
Whatever tool you use for coding, the quality of your transcripts directly affects how fast you can move through the analysis.
For example, transcripts without speaker labels force you to re-listen to the audio to figure out who said what. Transcripts without timestamps make it impossible to spot-check a quote against the recording without scrubbing through the entire file. Wall-of-text formatting slows down visual scanning and makes it harder to isolate codable segments.
This is where the transcription step and the analysis step connect, and where HappyScribe adds the most value for research workflows. Every transcript comes with automatic speaker identification, timestamped paragraphs, and structured formatting that QDA software can parse on import.
For research teams managing dozens of interviews across multiple coders, the consistency of the formatting ensures that everyone is working from identically structured transcripts.
FAQs on how to analyze interview transcripts in qualitative research
How many interview transcripts do I need for thematic analysis?
There is no universal number. For qualitative interviews based on in depth conversations, 12 to 25 participants is common across most organizations. The guiding principle is saturation: when new codes and common themes stop emerging from the data set. Your research objectives, research topic, and interview guide scope all influence the right number. For IPA studies focused on deeper understanding of individual experience, 3 to 10 participants is typical.
What is the difference between a code and a theme in qualitative data analysis?
A code is a short label you assign codes to specific segments of raw data during systematic coding. A theme groups coded data into a broader pattern of meaning relative to your research questions. Codes are building blocks; themes are structures built from them. During initial coding, you label passages, then look for common themes to begin producing findings and surface key insights.
Should I use inductive or deductive coding?
Exploratory research calls for inductive coding, where new codes emerge from the data collected. Studies with a theoretical framework call for deductive coding using predefined codes. Many qualitative researchers use both. Whichever coding method you choose, writing memos helps capture deeper meanings and important insights. The goal is to move from words spoken by participants to meaningful insights that support a broader perspective on your research topic.
Can AI tools help me analyze qualitative data from interview transcripts?
AI analysis can help analyze qualitative data faster by generating word clouds, flagging key themes, and surfacing actionable insights from multiple sources, including focus groups and survey responses. HappyScribe's AI Chat lets you compare participant responses and pull exact quotes on the same platform where your transcript files live. However, always validate themes and review analyzed data. AI accelerates the mechanical parts of the research process but cannot replace interpretive judgment.
How do I ensure intercoder reliability when analyzing interview transcripts?
Have each member of the research team independently code a subset of the qualitative data (usually 10-20%), compare outputs, and resolve disagreements. This critical step prevents common mistakes in large projects. Establish a shared codebook before the first interview round of data analysis begins. Analysis software like NVivo helps you manage coded data across your full data set. Report agreement levels in your methodology.

Rodoshi Das
Rodoshi is the content lead at HappyScribe, the privacy-first transcription and AI notetaker platform based in Barcelona. Shaping content strategies and building AI workflows excites her as much as exploring new SaaS tools. She specializes in product-led content that informs rather than sells, grounded in honest product benchmarking and a professionally low tolerance for empty marketing speak.