![Wie validieren Sie die Transkriptionsgenauigkeit in der qualitativen Forschung? [inkl. Checkliste]](/sanity-images/ejgwz1gl/redesign/eb4d668bc95b38859cee00050ec27a38d3e8a075-1536x1024.jpg?auto=format&w=1536.0&rect=0,128,1536,768&h=768)
Ein übersehener Kontext in einem Transkript kann ein Forschungsergebnis schnell verändern. Wenn ein Teilnehmer sagt „Ich habe mich nie unterstützt gefühlt“ und dies als „Ich habe mich immer unterstützt gefühlt“ transkribiert wird, kann das ein Thema verzerren und zu einer Schlussfolgerung führen, die Ihre Daten nicht stützen.
In der qualitativen Forschung hängt alles Weitere davon ab, was im Transkript steht. Deshalb ist die Validierung eine methodische Voraussetzung – sie stellt sicher, dass Ihre Forschung einer Peer-Prüfung standhält.
Dieser Leitfaden zeigt, wie Sie die Transkriptionsgenauigkeit in der qualitativen Forschung validieren: die Fehlerarten, die die Validität beeinträchtigen, einen Schritt-für-Schritt-Validierungsprozess, wie die KI-Transkription diesen Workflow verändert, und eine praktische Checkliste, die Sie ab Ihrem nächsten Projekt anwenden können.
📚 Auch lesenswert:
Warum die Transkriptionsgenauigkeit in der qualitativen Forschung wichtig ist
In der qualitativen Forschung ist das Transkript der primäre Datensatz, mit dem Sie arbeiten. Anders als in der quantitativen Forschung, wo sich Rohdaten aus Statistiken ableiten lassen, ergeben sich qualitative Erkenntnisse aus den Worten, die die Teilnehmenden tatsächlich verwendet haben, aus der gewählten Formulierung, aus ihrem Zögern und aus der Art, wie sie ihre Gedanken eingeordnet haben.
1. Transkriptionsfehler können sich unbemerkt ausbreiten
Das Problem mit kleinen Fehlern ist, dass sie sich nicht eingrenzen lassen. Ein Substitutionsfehler kann zum Beispiel die Aussage ins Gegenteil verkehren, und eine Auslassung nimmt einem Zitat den Kontext, der sonst zu einem Thema geführt hätte.
Wenn Sie in einer Fokusgruppe Sprecher falsch zuordnen, codieren Sie am Ende die Perspektive der falschen Person in Ihre Analyse. Diese Fehler treten häufiger auf, als Sie denken, und sie schleichen sich unbemerkt ein.
2. Sie sind dafür verantwortlich, die Stimmen der Teilnehmenden getreu wiederzugeben
Es gibt eine ethische Dimension, die Forschende manchmal unterschätzen. Teilnehmende geben ihre Zeit, ihre Erfahrungen und in Befragungen oft auch ihr Vertrauen. Wenn ein Transkript verfälscht, was sie gesagt haben, ersetzt es ihre Stimme durch eine Annäherung.
In einer Forschung, die sich auf gelebte Erfahrungen konzentriert, ist diese Annäherung ein Versagen Ihrer ethischen Verantwortung gegenüber den Menschen, die zu Ihrer Studie beigetragen haben.
3. Genaue Transkripte dienen als belastbarer Prüfpfad
Wenn ein Gutachter einer Fachzeitschrift oder ein Prüfer Ihrer Dissertation nachvollziehen möchte, wie Ihre Themen aus Ihren Daten entstanden sind, sind Ihre Transkripte das Erste, was er prüft.
Ein ungenaues Transkript schwächt nicht nur diese Kette, sondern stellt auch den gesamten analytischen Prozess infrage.
📚Auch lesenswert:
Arten von Transkriptionsfehlern, die die Validität der Forschung beeinträchtigen
Nicht alle Transkriptionsfehler sehen gleich aus, und manche sind schwerer zu erkennen als andere. Bevor Sie ein Transkript validieren können, müssen Sie wissen, wonach Sie suchen.
- Substitutionen treten auf, wenn ein Wort durch ein anderes ersetzt wird. Sie sind die gefährlichsten, weil sie die Bedeutung verändern können, ohne auf der Seite falsch auszusehen
- Auslassungen treten auf, wenn Wörter oder Phrasen ganz aus dem Transkript verschwinden. Ein gelöschter Teilsatz kann der Aussage eines Teilnehmers Nuancen oder Einschränkungen nehmen
- Einfügungen sind das Gegenteil: Wörter, die hinzugefügt wurden, aber nie gesprochen wurden. Sie schleichen sich ein, wenn eine transkribierende Person bei einer unklaren Passage ergänzt, was ihrer Meinung nach gesagt wurde
- Kontextfehler betreffen übersehene nonverbale Signale wie Pausen, Lachen oder stimmliche Betonung. In der wörtlichen Transkription haben diese analytisches Gewicht, und ihr Fehlen kann die Daten verflachen
- Falsche Sprecherzuordnung ordnet eine Aussage dem falschen Teilnehmer zu. In Aufnahmen mit mehreren Sprechern wie Fokusgruppen verfälscht das Ihre Codierung von Grund auf
- Durch Voreingenommenheit entstandene Fehler treten auf, wenn die Interpretation der transkribierenden Person das überlagert, was tatsächlich gesagt wurde. Das passiert häufiger, wenn der Inhalt mehrdeutig ist und die transkribierende Person sich auf das verlässt, was „richtig“ klingt, statt auf das, was gesprochen wurde
So validieren Sie die Transkriptionsgenauigkeit: Schritt-für-Schritt-Anleitung
1. Führen Sie einen vollständigen Audio-Text-Abgleich durch
Spielen Sie die gesamte Aufnahme ab, während Sie das Transkript von Anfang bis Ende lesen. Hier markieren Sie jede Abweichung zwischen dem Gesagten und dem Transkribierten.
Achten Sie besonders auf Abschnitte mit überlappenden Sprechbeiträgen, schlechter Audioqualität oder emotional aufgeladenen Antworten, denn dort häufen sich die Fehler.
Wenn Sie in einem interaktiven Transkript-Editor arbeiten, können Sie hier viel Zeit sparen. Der Editor hebt den Text synchron zur Audiowiedergabe hervor, kennzeichnet die Sprecher farblich und lässt Sie die Wiedergabegeschwindigkeit anpassen, sodass Sie Aufnahmen mit mehreren Teilnehmenden verfolgen können, ohne den Faden zu verlieren.
2. Nutzen Sie die Word Error Rate (WER) für ein quantitatives Benchmarking
Die WER liefert Ihnen ein numerisches Maß für die Transkriptionsgenauigkeit. Die Formel ist einfach: (Substitutionen + Einfügungen + Löschungen) / Gesamtzahl der Wörter im Referenztranskript. Eine WER von 0,05 bedeutet, dass 5 % der Wörter Fehler enthalten.
Die WER ist eine zentrale Kennzahl, wenn Sie KI-generierte Transkripte vor der menschlichen Überprüfung benchmarken. Berechnen Sie die WER an einer Stichprobe, bestimmen Sie den Schwellenwert, den Ihre Forschung tolerieren kann, und entscheiden Sie anhand des Ergebnisses, wie viel manuelle Korrektur nötig ist. Die WER erfasst weder Kontextfehler noch übersehene nonverbale Signale, behandeln Sie sie daher als Filter für den ersten Durchgang.
3. Führen Sie Member-Checking durch
Beim Member-Checking senden Sie die Transkripte an die Teilnehmenden zurück, damit diese überprüfen können, was erfasst wurde. Es ist eine von vier Glaubwürdigkeitstechniken in Lincoln und Gubas Vertrauenswürdigkeitsmodell, neben langfristigem Engagement, Peer-Debriefing und Triangulation.
Der Vorteil liegt auf der Hand: Teilnehmende können Fehler erkennen, die Ihnen entgehen würden – besonders rund um Absicht, Betonung oder kulturell spezifische Sprache. Doch es gibt Grenzen, die Sie im Blick behalten sollten. Manche Teilnehmende sind verlegen, wenn sie ihre gesprochene Sprache schriftlich sehen, während andere Aussagen zurücknehmen oder abschwächen möchten, die sie im Moment gemacht haben. Bauen Sie diese Möglichkeiten in Ihr Protokoll ein, damit Sie einen klaren Prozess für den Umgang mit Überarbeitungen gegenüber Rücknahmen haben.
4. Nutzen Sie Peer-Debriefing und unabhängige Überprüfung
Ein frischer Blick kann Ihnen helfen, Verzerrungen zu überwinden. Lassen Sie eine zweite forschende Person oder eine Kollegin eine Stichprobe der Transkripte gegen das Originalaudio prüfen, mit Fokus auf Passagen, die für Ihre Codierung entscheidend sind. Wenn zwei Prüfende im selben Abschnitt unterschiedliche Fehler markieren, ist das ein Signal, dass diese Passage genauer betrachtet werden muss.
Dieser Schritt funktioniert auch als Reliabilitätsprüfung. Wenn unabhängige Prüfende sich über die Transkriptgenauigkeit einig sind, stärkt das die Glaubwürdigkeit Ihres Datensatzes.
5. Standardisieren Sie ein Transkriptionsprotokoll
Wenn Sie im Team arbeiten, definieren Sie Ihre Notationskonventionen, bevor jemand mit dem Transkribieren beginnt. Dazu gehört, wie Sie Pausen, überlappende Sprechbeiträge, unhörbare Segmente und emotionalen Tonfall kennzeichnen. Ohne ein gemeinsames Protokoll werden Inkonsistenzen zwischen den Transkripten unvermeidlich, besonders in teambasierten Projekten.
Eftekhari (2024) skizziert einen praxisnahen Rahmen für Transkriptionsprotokolle in der qualitativen Forschung, einschließlich des Umgangs mit dem Übergang von manuellen zu KI-gestützten Workflows. Wenn Ihr Team die Transkription auf mehrere Personen aufteilt, hält ein dokumentiertes Protokoll Ihre Daten konsistent.
6. Führen Sie Konsistenzprüfungen über alle Transkripte hinweg durch
Sobald die einzelnen Transkripte validiert sind, prüfen Sie die Konsistenz über Ihren gesamten Datensatz hinweg. Überprüfen Sie Teilnehmernamen, Ortsnamen, Fachbegriffe, Sprecherkennzeichnungen und Zeitstempel, um sicherzustellen, dass alles mit dem Audio übereinstimmt.
Diese Prüfungen sind mühsam, aber sie verhindern Verwirrung während der Codierung und machen Ihren Prüfpfad leichter nachvollziehbar.
KI-Transkription und Validierung: Wie sich der Workflow verändert
Wussten Sie schon? Laut einer Untersuchung von McKinsey nutzen 79 % der Organisationen generative KI, um Arbeit zu beschleunigen.
Die KI-Transkription hat verändert, wie Forschende mit qualitativen Daten umgehen. Der grundlegende Workflow ist ein anderer – und das gilt auch für die Fehler, auf die Sie achten müssen.
- Die KI erstellt einen ersten Entwurf in Minuten statt in Stunden, doch ihre Fehler sind schwerer zu erkennen. KI-generierter Text ist grammatikalisch flüssig, sodass ein ersetztes Wort auf der Seite korrekt aussehen kann, während es die Bedeutung einer Aussage verändert
- Der sich abzeichnende Standard für die Transkription in der Forschung ist ein KI-plus-Mensch-Workflow. Die KI erstellt das Transkript, und eine menschliche prüfende Person validiert es gegen das Originalaudio. Keiner der beiden Schritte ersetzt den anderen
- Die menschliche Überprüfung muss weiterhin denselben oben beschriebenen Validierungsschritten folgen: vollständiger Audio-Text-Abgleich, Member-Checking sofern angebracht und Konsistenzprüfungen über alle Transkripte hinweg
- Wenn Sie ein cloudbasiertes KI-Tool verwenden, wird Ihr IRB, REC, IEC oder regionales Ethikgremium von Ihnen wahrscheinlich verlangen, dies in Ihren Unterlagen offenzulegen. Bevor Sie sich für eine Plattform entscheiden, klären Sie, wo Ihre Daten gespeichert werden, ob Dateien während der Übertragung und im Ruhezustand verschlüsselt sind und welche Compliance-Zertifizierungen der Anbieter besitzt
Tools, die Ihnen helfen, die Transkriptionsgenauigkeit in der Forschung zu verbessern
HappyScribe
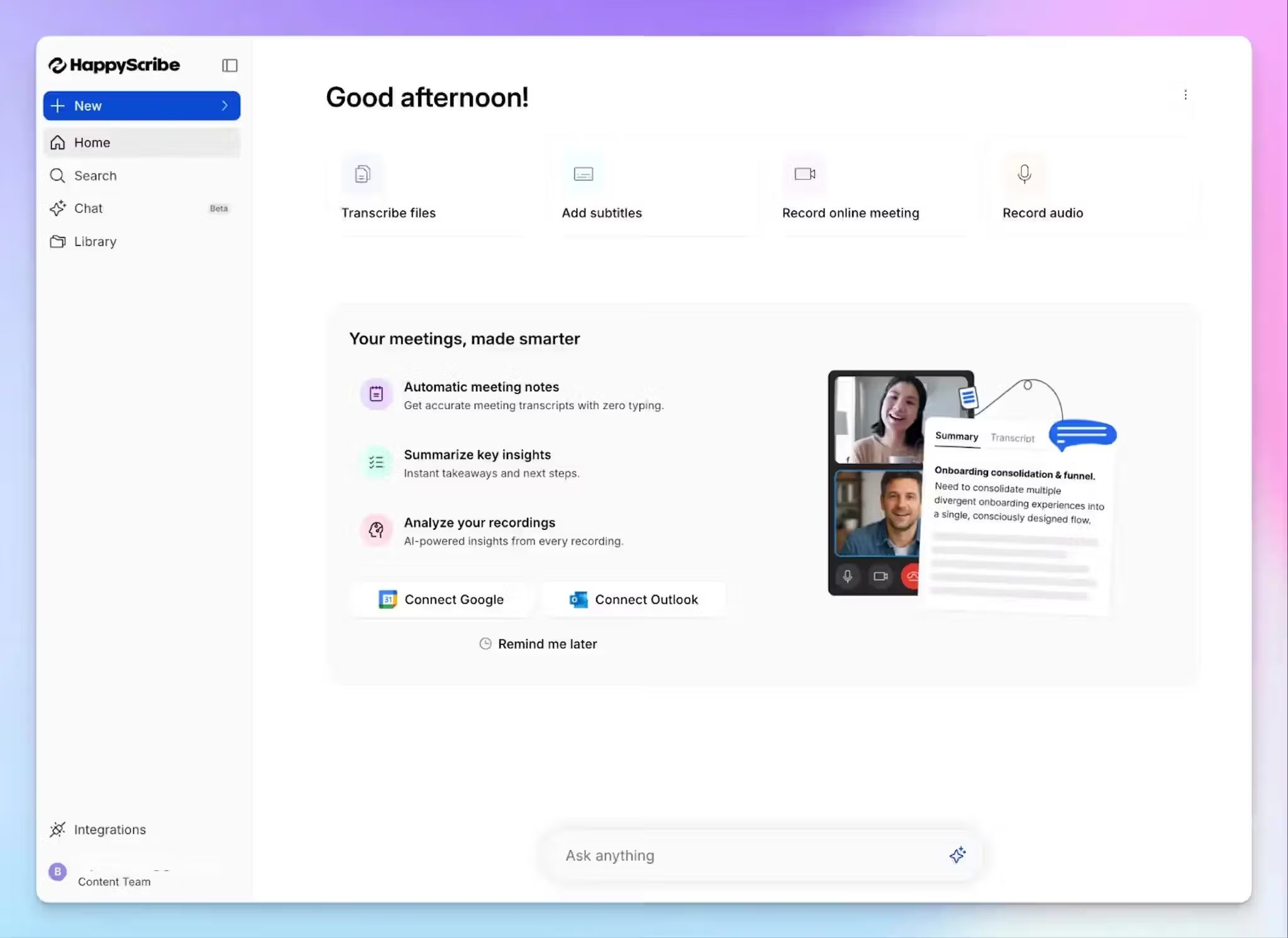
Für qualitativ Forschende besteht das Kernproblem darin, dass die Transkription sowohl zeitintensiv als auch folgenreich ist. HappyScribe ist für Forschende gemacht, die Geschwindigkeit und Flexibilität wollen, ohne dabei auf Genauigkeit zu verzichten.
Mit API-, MCP-Server- und Zapier-Integrationen sowie Unterstützung für Übersetzung und Untertitelung hilft Ihnen HappyScribe dabei, Forschungs-Workflows zu erweitern, ohne für weitere Tools zu bezahlen.
Optionen für KI- und menschliche Transkription
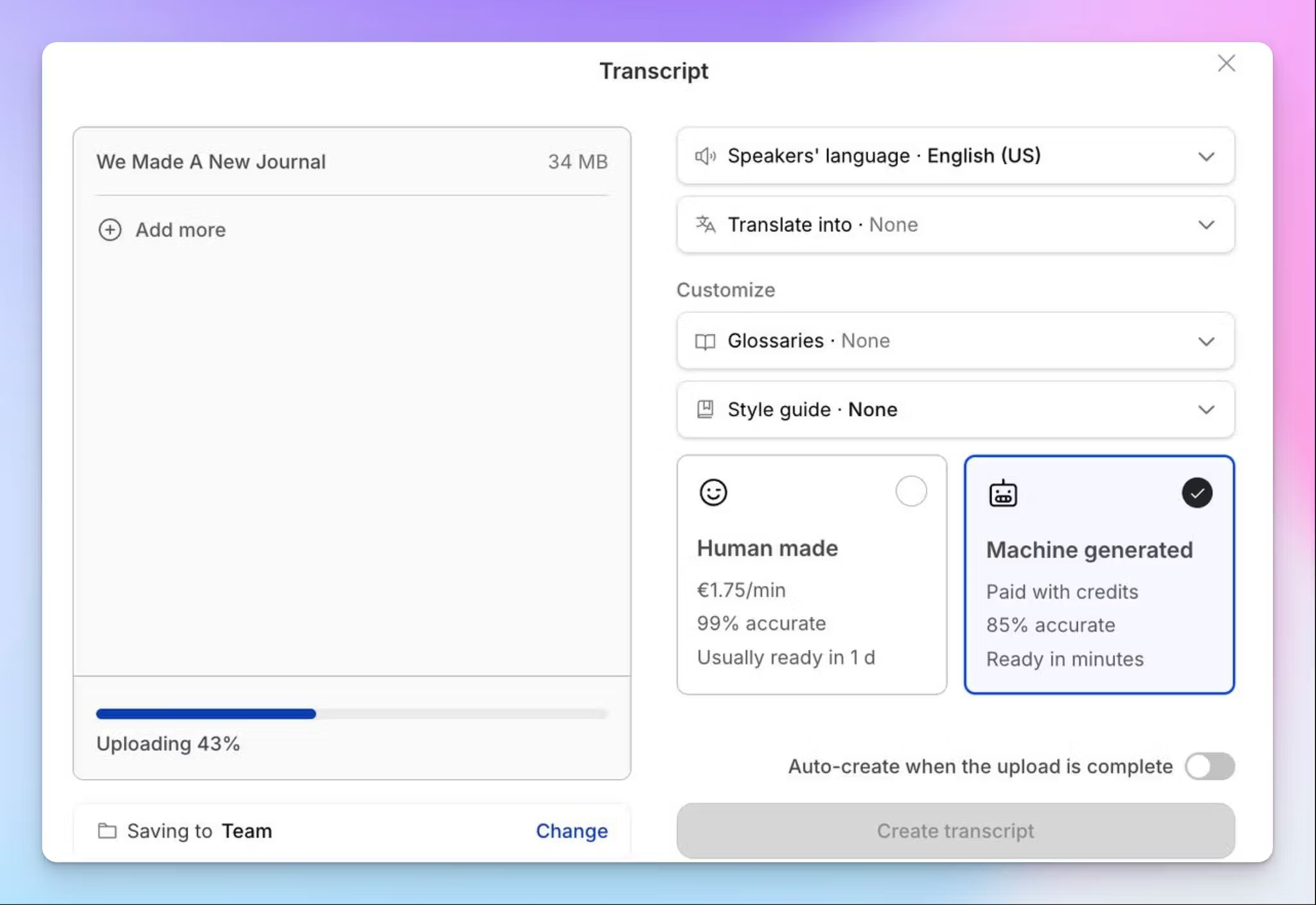
Mit HappyScribe können Sie KI-Transkriptionen in über 150 Sprachen ausführen, um in wenigen Minuten ein erstes Transkript zu erstellen. Wenn Ihr Projekt geprüfte Genauigkeit erfordert, können Sie die Mediendatei oder das Transkript an einen erfahrenen Sprachexperten senden, der es auf 99 % Genauigkeit bringt. Für qualitativ Forschende bedeutet das, dass Sie sich nicht zwischen Geschwindigkeit und Genauigkeit entscheiden müssen und sowohl mit KI als auch mit menschlichen Fachleuten arbeiten können.
Interaktiver Transkript-Editor
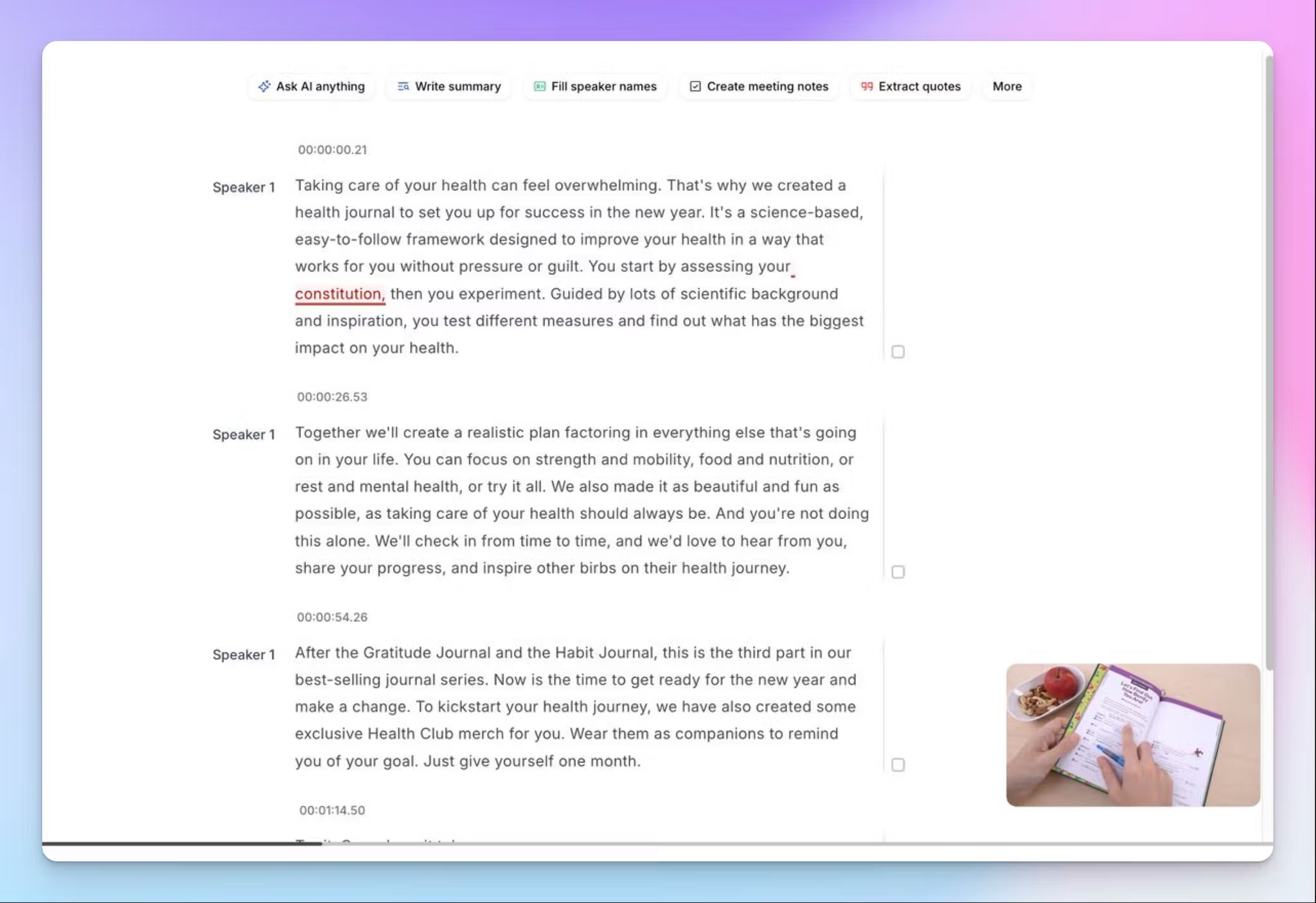
Der Validierungsprozess, den ich zuvor skizziert habe, hängt davon ab, dass Sie Audio und Text effizient vergleichen können. Mit dem Editor von HappyScribe können Sie gleichzeitig hören und lesen, die Wiedergabegeschwindigkeit anpassen, nach Begriffen suchen, Passagen hervorheben und Fehler direkt im Text korrigieren. Sie können außerdem Teammitglieder einladen, was für größere Projekte nützlich ist, die mehrere Überprüfungsrunden durchlaufen.
Tiefere Erkenntnisse mit AI Chat finden

Sobald Sie alle Transkriptdaten haben, können Sie HappyScribe AI Chat nutzen, um zentrale Erkenntnisse, Beobachtungen und Muster aufzudecken, die Ihnen beim Durchsehen der Transkripte vielleicht entgangen sind. Der AI Chat ist für tiefgehende Konversationen konzipiert, sodass Sie ihn bitten können, alle Dateien zu durchsuchen und Sie bei Zusammenfassungen, Entwürfen und Zitaten zu unterstützen.
Sprechererkennung und Zeitstempel
HappyScribe identifiziert und kennzeichnet die Sprecher automatisch über das gesamte Transkript hinweg. Da die Zeitstempel auf Wortebene angefügt sind, können Sie jede Passage mit dem Originalaudio abgleichen, ohne die gesamte Aufnahme durchzuspulen.
DSGVO-konform und SOC 2 Type II zertifiziert
Wenn Sie einen Ethikantrag oder ein IRB-Protokoll einreichen, das eine cloudbasierte Transkription umfasst, werden Sie möglicherweise gefragt, wie die Daten der Teilnehmenden gespeichert und geschützt werden. HappyScribe verfügt über die SOC 2 Type II Zertifizierung, was bedeutet, dass es regelmäßig von einem unabhängigen Team auf Sicherheit und Systemintegrität geprüft wird.
Dank DSGVO-Konformität und Datenspeicherung in der EU haben Teilnehmende mehr Kontrolle über Datenschutz und Einwilligung. Wenn diese Zertifizierungen von Anfang an dokumentiert sind, wird der Prozess der Ethikfreigabe unkomplizierter.
Weitere Tools, die für die qualitative Forschung einen Blick wert sind
1. ATLAS.ti
ATLAS.ti ist ein Tool zur Analyse qualitativer Daten. Es übernimmt Codierung, Themenidentifikation und Netzwerkvisualisierung, sobald Sie bereits ein sauberes Transkript zur Hand haben. Wenn Sie HappyScribe oder ein anderes Transkriptionstool nutzen, um Ihre Transkripte zu erstellen und zu überprüfen, kann ATLAS.ti für die Analyse nützlich sein.
2. Otter
Otter ist ein KI-gestütztes Transkriptionstool, das primär für Meetings entwickelt wurde. Es zeichnet Gespräche auf Zoom, Google Meet und Microsoft Teams auf, erstellt Transkripte und produziert KI-Zusammenfassungen.
Allerdings unterstützt Otter nur 6 Sprachen, was für Nutzende, die mit mehrsprachigen Interviewdaten arbeiten, eine erhebliche Einschränkung darstellt. Der Pro-Tarif startet bei 16,99 $/Monat, begrenzt Sie aber auf 1.200 Minuten und 10 Datei-Importe pro Monat, sodass große Datenbanken mit vorab aufgezeichneten Interviews tabu sind.
3. Rev
Die Kernstärke von Rev ist die von Menschen erstellte Transkription mit angeblich 99 % Genauigkeit und einer typischen Bearbeitungszeit von 12–24 Stunden, was es zu einer verlässlichen Option für Forschende macht, die einen vollständig menschlichen Workflow wünschen. Rev bietet außerdem KI-Transkription und Dateianalyse. Beachten Sie, dass Rev nicht die günstigste Option auf dem Markt ist und bei umfangreichen Projekten die Rechnungen schnell ansteigen.
Checkliste zur Transkriptionsgenauigkeit für qualitativ Forschende
Nutzen Sie diese Checkliste als schnelle Referenz vor, während und nach der Transkription. Jeder Schritt wird weiter oben in diesem Leitfaden ausführlich behandelt.
| Phase | Maßnahme |
|---|---|
| Vor der Transkription |
|
| Während der Transkription |
|
| Nach der Transkription |
|
Validieren Sie Ihre Transkripte, bevor Sie darauf aufbauen
Die Validierung von Transkripten ist nichts, was man einmal erledigt und dann vergisst. Es ist ein mehrstufiger Prozess, bei dem jeder Schritt erfasst, was der vorherige übersehen hat.
Ein vollständiger Audio-Text-Abgleich deckt Fehler auf, die die WER nicht quantifizieren kann, und Member-Checking bringt Verfälschungen ans Licht, die selbst einer sorgfältigen prüfenden Person entgehen. Indem Sie Konsistenzprüfungen über den gesamten Datensatz durchführen, verhindern Sie, dass sich kleine Abweichungen während der Codierung aufsummieren.
Doch ein gründlicher Prozess funktioniert nur, wenn Ihre Tools ihn unterstützen. Wenn Sie zwischen einem Transkriptionsdienst, einem separaten Audioplayer und einer Tabelle zum Nachverfolgen von Korrekturen hin- und herwechseln, dauert die Validierung länger und Fehler rutschen durch die Lücken zwischen den Tools.
HappyScribe vereint Transkription, Überprüfung und Zusammenarbeit in einer Plattform. Sie können KI-Transkripte erstellen, bei kritischer Genauigkeit zur menschlichen Korrektur eskalieren und Ihren gesamten Validierungs-Workflow im Editor ausführen.
Häufige Fragen dazu, wie man die Transkriptionsgenauigkeit in der qualitativen Forschung validiert
Was ist Member-Checking bei der Validierung von Transkripten?
Member-Checking ist, wenn Sie die Transkripte an die Teilnehmenden zurücksenden, damit diese überprüfen können, was während des Interviewprozesses erfasst wurde. Es ist eine Glaubwürdigkeitstechnik aus Lincoln und Gubas Vertrauenswürdigkeitsmodell und hilft Ihnen, Fehler in Bezug auf Absicht, Betonung oder kulturell spezifische Sprache zu erkennen, die einer prüfenden Person entgehen könnten. Die Einschränkung ist, dass sich manche Teilnehmende unwohl fühlen, wenn sie ihre gesprochene Sprache in schriftlicher Form sehen, und andere Aussagen zurücknehmen möchten.
Erstellen Sie ein klares Protokoll für den Umgang mit diesen Situationen, bevor Sie den Transkriptionsprozess beginnen, damit Sie keine spontanen Entscheidungen über Überarbeitungen treffen müssen, während die Transkription der qualitativen Forschung läuft. Member-Checking reduziert außerdem mögliche Verzerrungen, die sich einschleichen können, wenn eine einzelne forschende Person darüber bestimmt, wie alle Interviews dargestellt werden.
Wie berechnet man die Word Error Rate (WER) für ein Transkript?
Die WER misst, wie weit ein Transkript von einer Referenzversion abweicht. Die Formel lautet (Substitutionen + Einfügungen + Löschungen) / Gesamtzahl der Wörter im Referenztranskript. Eine WER von 0,05 bedeutet, dass 5 % der Wörter Fehler enthalten. Sie ist am nützlichsten zum Benchmarking von KI-generierten Transkripten, die auf Spracherkennung und natürlicher Sprachverarbeitung beruhen, bevor Sie zur menschlichen Überprüfung übergehen. Die WER erfasst weder Kontextfehler noch übersehene nonverbale Signale, daher funktioniert sie am besten als Filter für den ersten Durchgang einer genauen Transkription und nicht als vollständige Validierungsmethode. Sie benötigen weiterhin einen vollständigen Audio-Text-Abgleich, um zu erfassen, was die WER übersieht.
Wie genau ist die KI-Transkription für die qualitative Forschung?
Die meiste auf Spracherkennung basierende Transkriptionssoftware liefert bei sauberen Audioaufnahmen eine Genauigkeit von 85–95 %. Das klingt hoch, doch in einem Transkript mit 10.000 Wörtern bedeuten selbst 5 % Fehler 500 falsche Wörter, und einige dieser Fehler landen in analytisch entscheidenden Passagen. Für die qualitative Forschung, in der die transkribierten Daten der primäre Datensatz sind, ist diese Fehlerspanne ohne menschliche Überprüfung nicht akzeptabel. HappyScribe begegnet dem, indem Sie die KI-Transkription für einen schnellen ersten Entwurf nutzen und dann zur menschlichen Korrektur eskalieren können, die die Genauigkeit auf 99 % bringt.
Was ist der Unterschied zwischen wörtlicher und intelligenter wörtlicher Transkription?
Die wörtliche Transkription erfasst alles: Füllwörter, Fehlstarts, Wiederholungen, Pausen, Lachen und nonverbale Kommunikation. Die intelligente wörtliche Transkription bereinigt den Text, indem sie Füllwörter und Wiederholungen entfernt, während die Bedeutung des Gesagten erhalten bleibt. Die richtige Wahl hängt von Ihrer qualitativen Analysemethode ab.
Wenn Sie eine thematische Analyse durchführen, bei der Sie nach gemeinsamen Themen und Mustern über die Teilnehmenden hinweg suchen, reicht die intelligente wörtliche Transkription meist aus, weil sich die Datenanalyse auf die Bedeutung und nicht auf die Darbietung konzentriert. Und wenn Ihre Forschung davon abhängt, wie etwas gesagt wurde, etwa bei der Konversationsanalyse oder Diskursanalyse, ist die wörtliche Transkription die einzige Option, weil das Entfernen von Füllwörtern den Daten die Details nimmt, die Sie für die Analyse benötigen.
Wie lange dauert es, ein Transkript aus der qualitativen Forschung zu validieren?
Ein vollständiger Audio-Text-Abgleich eines einzelnen 60-minütigen Interviews dauert in der Regel 2–3 Stunden, wenn Sie sorgfältig prüfen. Der genaue Zeitrahmen hängt von der Länge der Aufnahme, der Audioqualität und der Anzahl der Validierungsschritte in Ihrem Protokoll ab. Rechnen Sie Member-Checking, Peer-Debriefing und Konsistenzprüfungen über Ihren Datensatz hinzu, und Sie haben deutlich mehr Zeit pro Transkript einzuplanen.
Bei Projekten mit großen Mengen an Interviewtranskripten oder Videodaten kann die Validierungsphase genauso lange dauern wie die Phase der Datenerhebung selbst. Wenn Sie die KI-Transkription für den ersten Entwurf nutzen, verkürzt das die anfängliche Umwandlung gesprochener Worte in Text auf wenige Minuten, was Ihnen mehr Zeit für die Validierung gibt, die Ihre Forschungsergebnisse vor Datenverlust und Ungenauigkeit schützt.
Was sollte ein Transkriptionsprotokoll für die qualitative Forschung enthalten?
Ihr Protokoll sollte die Notationskonventionen festlegen, bevor jemand im Team mit dem Transkribieren beginnt. Dokumentieren Sie mindestens, wie Sie Pausen, überlappende Sprechbeiträge mehrerer Sprecher, unhörbare Segmente und emotionalen Tonfall kennzeichnen. Legen Sie fest, ob Sie wörtliche oder intelligente wörtliche Transkription verwenden, und erläutern Sie, warum diese Wahl zu Ihrem qualitativen Analyseansatz passt.
Nehmen Sie Regeln für die Sprecherkennzeichnung, die Zeitstempelintervalle und den Umgang mit sensiblen Inhalten auf, bei denen ethische Erwägungen gelten. Wenn Ihre Institution oder Aufsichtsbehörden bestimmte Verfahren für den Umgang mit Daten aus Audioaufnahmen verlangen, dokumentieren Sie auch diese im Protokoll.
Ein starkes Protokoll hält die über alle Interviews erhobenen Daten konsistent, was Ihre thematische Analyse zuverlässiger und Ihren Prüfpfad leichter verteidigbar macht.

Biplab Mazumder
Biplab is a content marketer and writer who helps high-growth brands scale content visibility across AI search channels. His works have been published in HubSpot, Freshworks, Atlassian, SurferSEO, etc. When he's not planning content strategy, he's testing AI content workflows and use cases.





