Wenn Menschen fragen, ob Sprecherbezeichnungen oder Zeitstempel die Transkription verlangsamen, stellen sie in der Regel die falsche Frage.
Die eigentliche Frage ist nicht, wie schnell ein Transkript geliefert wird, sondern wie schnell es nutzbar wird.
Bei Interviews, juristischen Aufnahmen, akademischer Forschung und Untertiteln verursacht ein Transkript, das zwar schnell geliefert wird, aber keine Struktur hat, mehr Arbeit als es einspart. Wenn Redakteure den Ton wiederholt durchgehen, werden die Überprüfungszyklen länger als üblich.
In diesem Artikel erkläre ich, was die Geschwindigkeit und Qualität der Transkription tatsächlich beeinflusst. Außerdem werde ich erörtern, ob Sprecherbezeichnungen und Zeitstempel helfen oder schaden. Los geht's!
TL;DR
- Les étiquettes de locuteurs et les horodatages ne ralentissent pas significativement le processus de conversion audio en texte ou vidéo en texte. Les deux sont générés automatiquement dans le cadre du pipeline de transcription.
- La vitesse de transcription est bien plus influencée par la qualité audio, le nombre de locuteurs, les chevauchements de parole et l’accent que par l’ajout de structure.
- Les étiquettes de locuteurs réduisent le temps de relecture en facilitant le suivi des conversations, l’attribution des citations et la navigation dans les transcriptions.
- Les horodatages sont générés pendant la transcription, pas après. Ils font gagner du temps lors de l’édition, du sous-titrage et de la référence.
Welche Faktoren beeinflussen die Geschwindigkeit und Qualität der Transkription?
Bevor wir Sprecherbezeichnungen oder Zeitstempel isoliert betrachten, ist es wichtig, die größeren Kräfte zu verstehen, die die Ergebnisse der Transkription beeinflussen.
1. Audioqualität und Sprecherüberlappung
Klarer Ton ist der wichtigste Faktor für Geschwindigkeit und Genauigkeit der Transkription.
Hintergrundgeräusche, Durcheinanderreden, schlechte Tonqualität und uneinheitliche Mikrofonpegel verlangsamen die automatische Erkennung und erhöhen den Überprüfungsaufwand.
Überlappende Sprache ist besonders aufwendig, da sie sowohl die Sprecheridentifikation als auch die Satzgrenzen erschwert.
2. Anzahl der Sprecher und Häufigkeit des Sprecherwechsels
Ein Zwei-Personen-Interview mit klarem Sprecherwechsel verhält sich ganz anders als eine schnelle Podiumsdiskussion.
Mit zunehmender Sprecherzahl und häufigerem Sprecherwechsel wird die Struktur wichtiger. Ohne sie steigt der Überprüfungsaufwand schnell an.
3. Sprachkomplexität, Akzente und Fachbegriffe
Fachvokabular, akzentbehaftete Sprache und mehrsprachige Aufnahmen erhöhen das Auftreten von Erkennungsfehlern.
4. Überprüfungsworkflow: Reine KI-Transkription vs. menschlich unterstützte Transkription
Die anfängliche Liefergeschwindigkeit ist nur ein Teil der Gleichung. Reine KI-Transkripte kommen möglicherweise schneller, aber menschlich unterstützte Workflows reduzieren die Gesamtbearbeitungszeit, indem sie Korrekturen und erneutes Anhören minimieren.
Lesen Sie auch: Wie die Genauigkeit maschineller Übersetzung gemessen wird
Verlangsamt die Sprecheridentifikation die Transkription?
Das Hinzufügen von Sprecherbezeichnungen wirkt wie zusätzliche Arbeit, sodass man leicht annimmt, dass sie den Prozess verlangsamen. In der Praxis ist das aber meist nicht der Fall. Was sich ändert, ist der Aufwand, der nach der Lieferung des Transkripts erforderlich ist.
Was die Sprecheridentifikation (Diarisierung) tatsächlich bewirkt
Die Sprecheridentifikation erkennt, wer wann gesprochen hat, und gruppiert die Sprachsegmente entsprechend. Moderne Systeme führen dies während der Transkription durch, sodass kein zusätzlicher manueller Schritt erforderlich ist.
Wann die Sprecheridentifikation Reibung verursachen kann
Bei Aufnahmen mit starken Hintergrundgeräuschen und ständigen Unterbrechungen oder sehr kurzen Äußerungen kann die Diarisierung eine zusätzliche Überprüfung erfordern. In diesen Grenzfällen kann die Identifikation geringfügig mehr Verarbeitungs- oder Überprüfungszeit bedeuten.
Wann die Sprecheridentifikation die Gesamtbearbeitungszeit verkürzt
Bei strukturierten Inhalten wie Interviews, Meetings, juristischen Aussagen oder qualitativer Forschung lassen sich beschriftete Transkripte schneller überprüfen und freigeben. Redakteure können den Dialog überfliegen und Zitate sicher zuordnen.
Warum unbeschriftete Transkripte oft länger zum Fertigstellen brauchen
Wenn Sprecher nicht identifiziert sind, gleichen die Prüfer dies manuell aus. Sie spielen Abschnitte erneut ab, um zu bestätigen, wer spricht, fügen selbst Bezeichnungen ein und überprüfen Querverweise. Die bei der Lieferung eingesparte Zeit geht bei der Fertigstellung verloren.
Verlangsamen Zeitstempel die Transkription?
Kurze Antwort: nicht so, wie die meisten Menschen annehmen.
Zeitstempel werden als zusätzliche Schicht betrachtet, die nach der Transkription hinzugefügt wird – etwas, das die Bearbeitungszeit erhöht.
In modernen Transkriptionssystemen funktioniert das jedoch nicht so. Die Zeitinformationen werden erzeugt, während die Sprache mit dem Text abgeglichen wird, sodass Zeitstempel standardmäßig keinen separaten Schritt einführen.
Wo die Zeiterfassung die Bearbeitungszeit beeinflussen kann, ist die Genauigkeit, mit der diese Zeitstempel mit dem Audio übereinstimmen müssen, und wie viel Korrektur bei der Überprüfung erforderlich ist.
Wie Zeitstempel während der Transkription erzeugt werden
Während das Audio verarbeitet wird, wird jedes gesprochene Segment bereits einem Zeitpunkt zugeordnet.
Zeitstempel auf Satzebene machen diese Zuordnung einfach sichtbar. Sie werden automatisch erzeugt und erfordern keine manuelle Eingabe, es sei denn, das Audio selbst ist unklar.
Zeitstempel auf Satzebene vs. auf Wortebene
Zeitstempel auf Satzebene sind schneller zu überprüfen und decken die meisten Anwendungsfälle ab, einschließlich Interviews, Untertitel und Dokumentation.
Zeitstempel auf Wortebene hingegen bieten eine feinere Kontrolle für die erweiterte Bearbeitung oder Analyse, erfordern aber eine strengere Ausrichtung und mehr Überprüfung.
Woher zeitstempelbezogene Verzögerungen kommen
Wenn Verzögerungen auftreten, resultieren sie in der Regel aus der Überprüfung und Korrektur der Ausrichtung.
Schlechte Audioqualität oder überlappende Sprache mit unklaren Satzgrenzen erschweren es, die Zeiterfassung sauber festzulegen.
Die Zeitstempel sind nicht die Ursache – die Komplexität des Audios ist es.
Warum präzise Zeitstempel später Zeit sparen
Präzise Zeitstempel reduzieren die Notwendigkeit, das Audio erneut anzuhören, wenn Sie Untertitel erstellen, juristisches Material referenzieren oder Clips extrahieren.
Anstatt durch Aufnahmen zu scrollen, können Teams direkt zum richtigen Moment springen, was die Überprüfungs- und Wiederverwendungszeit erheblich verkürzt.
Zeitstempel verlangsamen die Transkription selbst selten. Im Gegenteil, sie beschleunigen in der Regel alles, was danach kommt.
Lesen Sie auch: Die 5 besten Untertitel-Generatoren 2026
Warum das Entfernen von Sprecherbezeichnungen oder Zeitstempeln oft später mehr Zeit kostet
Auf dem Papier sieht das Entfernen von Sprecherbezeichnungen oder Zeitstempeln wie eine Möglichkeit aus, die Dinge zu beschleunigen. Das Transkript kommt schneller an, und alle Wörter sind da. In der Praxis zeigt sich die fehlende Struktur jedoch als Mehrarbeit bei der Überprüfung.
Manuelle Sprecheridentifikation während der Überprüfung
Wenn Sprecherbezeichnungen fehlen, müssen die Prüfer die Sprecher selbst identifizieren. Das bedeutet, Abschnitte erneut abzuspielen, Stimmen zuzuordnen und im Kopf zu behalten, wer wo spricht.
Bei längeren Aufnahmen oder Gruppengesprächen wird dies schnell mühsam und inkonsistent, besonders wenn mehrere Prüfer beteiligt sind.
Erneutes Anhören des Audios für Kontext und Referenzen
Ohne Zeitstempel verliert das Transkript seine direkte Verbindung zum Audio.
Ein Zitat zu finden, den Kontext zu überprüfen oder die Formulierung zu verifizieren bedeutet, die Aufnahme manuell durchzuscrollen.
Was eine schnelle Referenz sein sollte, wird zu wiederholtem Abspielen und schafft Reibung selbst bei einfachen Überprüfungsaufgaben.
Mehrarbeit bei Untertitelung, juristischer Prüfung und Forschungsanalyse
Untertitel hängen von präziser Zeiterfassung ab. Juristische Transkripte basieren auf klarer Zuordnung. In der Forschungsanalyse müssen Aussagen häufig mit bestimmten Momenten in der Aufnahme verknüpft werden.
Wenn Transkripte keine Sprecherbezeichnungen oder Zeitstempel enthalten, muss diese Information nachträglich rekonstruiert werden – in der Regel von jemandem, der das Original-Transkript nicht erstellt hat.
Versteckte Bearbeitungszeit jenseits der anfänglichen Lieferung
Die Verzögerung zeigt sich nicht bei der Lieferung des Transkripts. Sie tritt bei der Bearbeitung oder Freigabe zutage.
Jede fehlende Bezeichnung oder Zeitmarke fügt kleine Unterbrechungen hinzu, die sich über Teams und Dateien hinweg summieren. Dadurch verlängert sich die Gesamtzeit zur Fertigstellung eines Transkripts.
In den meisten Workflows reduziert die während der Transkription hinzugefügte Struktur die spätere Arbeit. Wenn diese Struktur entfernt wird, fällt dieselbe Arbeit trotzdem an – nur langsamer und weniger vorhersehbar.
Lesen Sie auch: Die 5 besten Gerichtstranskriptionsdienste für juristische Teams
Wie HappyScribe Sprecherbezeichnungen und Zeitstempel handhabt
Wenn Sie HappyScribe nutzen, um Audio in Text umzuwandeln oder Video in Text umzuwandeln, werden Sprecherbezeichnungen und Zeitstempel nicht nachträglich hinzugefügt, sondern sind von dem Moment an Teil des Prozesses, in dem Sie Ihre Datei hochladen.
Die KI von HappyScribe beginnt sofort zu arbeiten, sobald die Datei in Ihrem Dashboard erscheint, und erzeugt ein strukturiertes Transkript mit integrierten Zeitsignalen.
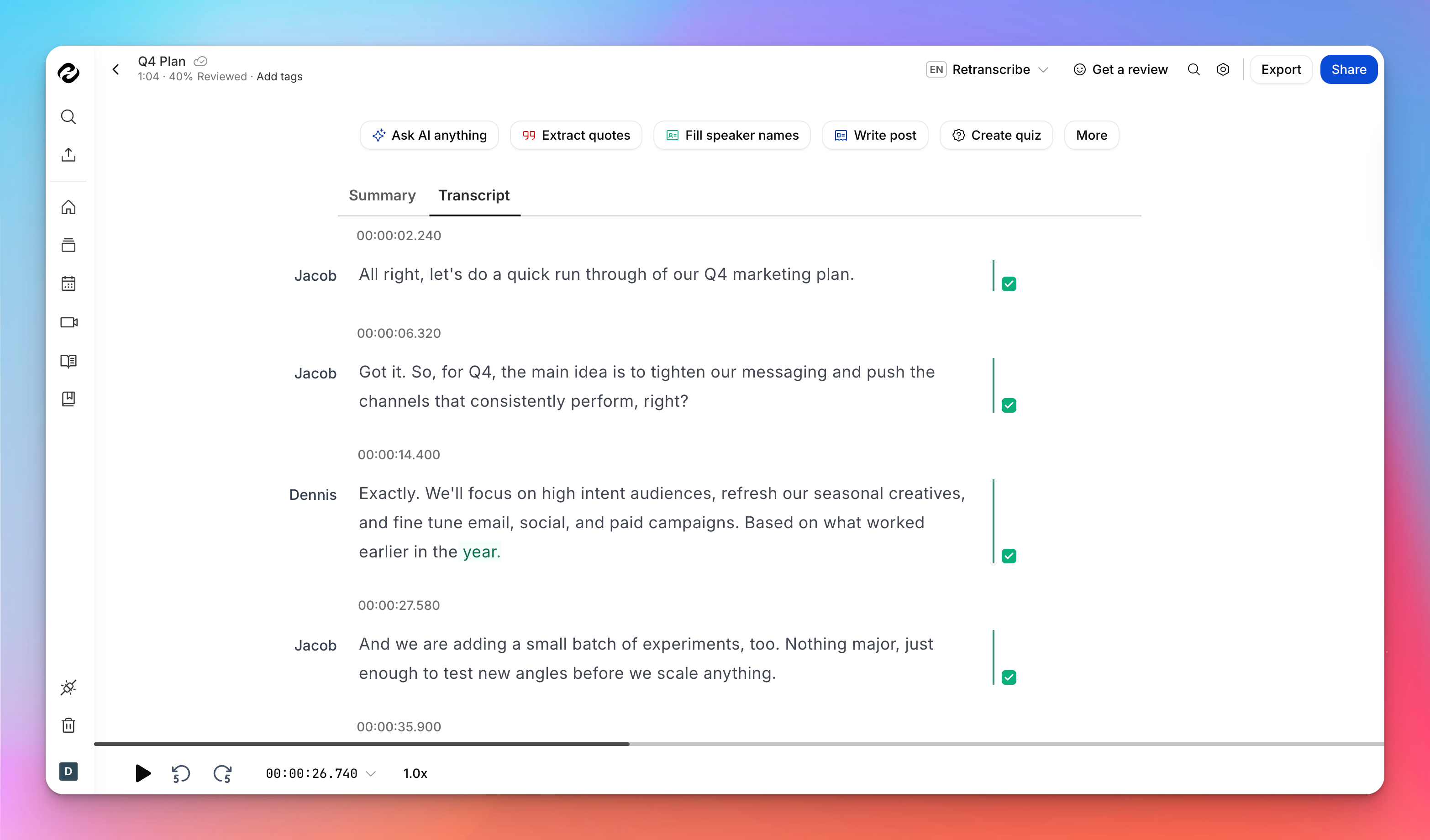
Auf der Verarbeitungsseite wird die automatische Transkription von HappyScribe bei den meisten Dateien in wenigen Minuten abgeschlossen, ohne dass Sie im Browser warten müssen.
Sobald das erste Transkript erstellt ist, können Sie es direkt im Editor überprüfen, bearbeiten und verfeinern.
Sprecherbezeichnungen sind bereits vergeben (Sie können Sprechernamen manuell hinzufügen), und Zeitstempel sind mit dem Audio synchronisiert, sodass Sie keine separaten Dateien verwalten oder die Struktur manuell hinzufügen müssen.
Beide Funktionen dienen praktischen Anwendungsfällen, bei denen Nachverfolgbarkeit entscheidend ist, einschließlich Interviews, Forschungstranskripten, Untertiteln und juristischer Dokumentation.
Bonus: Von Menschen erstellte Transkripte
HappyScribe bietet auch menschlich unterstützte Transkription als Option an.
In diesem Workflow überprüfen und optimieren professionelle Linguisten das Transkript für höhere Genauigkeit und konsistente Sprecheridentifikation. Die Bearbeitungszeit beträgt unter 24 Stunden für gängige Sprachen wie Englisch, Französisch und Spanisch.
Sie können von Menschen erstellte Transkripte in über 130 Sprachen erhalten.
Das eigentliche Problem hinter langsamer Transkription und wie Sie es lösen
Sprecherbezeichnungen und Zeitstempel verlangsamen die Transkription nicht in nennenswerter Weise. Was Teams ausbremst, ist das nachträgliche Korrigieren fehlender Strukturen.
Wenn Ihnen die tatsächliche Bearbeitungszeit wichtig ist, schauen Sie über die Liefergeschwindigkeit eines Transkripts hinaus. Messen Sie, wie lange es dauert, es zu überprüfen, Zitate zu verifizieren, Untertitel zu erstellen oder es für Forschung oder juristische Arbeit wiederzuverwenden. Dort zahlt sich Struktur aus.
Die einfachste Art zu entscheiden ist, es auszuprobieren. Nehmen Sie eine echte Aufnahme, transkribieren Sie sie mit aktivierten Sprecherbezeichnungen und Zeitstempeln, und beobachten Sie, wie viel weniger Zeit Sie für die Bearbeitung und Kontextprüfung aufwenden.
Wenn Sie sehen möchten, wie das in der Praxis funktioniert, testen Sie HappyScribe für Ihre nächste Datei und bewerten Sie den gesamten Workflow, nicht nur die Liefergeschwindigkeit.
FAQ
Wie funktioniert die Sprecheridentifikation beim Transkribieren von Audio mit mehreren Sprechern?
Beim Transkribieren von Audio mit mehreren Sprechern nutzen moderne KI-Transkriptionssysteme maschinelles Lernen, um verschiedene Stimmen, Sprechmuster und Pausen in der Audiospur zu erkennen. Dieser Prozess, auch als Sprecherdiarisierung bekannt, hilft bei der Identifizierung der Sprecher auch bei häufigen Sprecherwechseln. Die Genauigkeit verbessert sich bei klarem Audio und deutlich unterscheidbaren Sprechern, wird aber bei ähnlich klingenden Stimmen oder überlappender Sprache schwieriger. Verwenden Sie hochwertige Transkriptionstools wie HappyScribe für Meetings mit mehreren Sprechern.
Beim Transkribieren von Audio mit mehreren Sprechern nutzen moderne KI-Transkriptionssysteme maschinelles Lernen, um verschiedene Stimmen, Sprechmuster und Pausen in der Audiospur zu erkennen. Dieser Prozess, auch als Sprecherdiarisierung bekannt, hilft bei der Identifizierung der Sprecher auch bei häufigen Sprecherwechseln. Die Genauigkeit verbessert sich bei klarem Audio und deutlich unterscheidbaren Sprechern, wird aber bei ähnlich klingenden Stimmen oder überlappender Sprache schwieriger. Verwenden Sie hochwertige Transkriptionstools wie HappyScribe für Meetings mit mehreren Sprechern.
Was passiert mit Sprecherkennzeichnungen bei schlechter Audioqualität?
Schlechte Audioqualität, starke Hintergrundgeräusche oder inkonsistente Mikrofonpegel erschweren die zuverlässige Zuweisung von Sprecherkennzeichnungen. In solchen Fällen können Transkriptionstools unklare Abschnitte belassen oder sich auf Kontexthinweise stützen, was dann eine menschliche Überprüfung erfordert. Die Verwendung guter externer Mikrofone und die Aufnahme von sauberem Audio an der Quelle reduziert den manuellen Aufwand und führt zu genaueren Ergebnissen.
Schlechte Audioqualität, starke Hintergrundgeräusche oder inkonsistente Mikrofonpegel erschweren die zuverlässige Zuweisung von Sprecherkennzeichnungen. In solchen Fällen können Transkriptionstools unklare Abschnitte belassen oder sich auf Kontexthinweise stützen, was dann eine menschliche Überprüfung erfordert. Die Verwendung guter externer Mikrofone und die Aufnahme von sauberem Audio an der Quelle reduziert den manuellen Aufwand und führt zu genaueren Ergebnissen.
Sind Sprecherkennzeichnungen für Geschäftsmeetings und Gruppendiskussionen nützlich?
Ja. In Geschäftsmeetings, Gruppendiskussionen, Podiumsdiskussionen und wichtigen Gesprächen verhindern Sprecherkennzeichnungen Verwirrung, wenn mehrere Personen beitragen. Selbst generische Kennzeichnungen wie Sprecher A und Sprecher B helfen Prüfern nachzuvollziehen, wer was gesagt hat. Ohne Kennzeichnungen müssen Prüfer oft die Audioaufnahme erneut abspielen, um die Zuordnung zu bestätigen, was die Überprüfung verlangsamt.
Wie funktionieren Zeitstempel, und welches Zeitstempelformat sollte ich wählen?
Zeitstempel werden zur Ausrichtung von Sprache zu Text generiert. Die meisten Transkriptionsdienste bieten verschiedene Zeitstempeloptionen an, wie satz- oder wortweise Zeitstempel. Satzweise Zeitstempel eignen sich gut für Interviews (ob Audio- oder Videodateien) und Dokumentation. Wortweise Zeitstempel bieten eine genauere Kontrolle, sind aber zeitaufwändiger zu überprüfen, besonders wenn die Audiodatei Rauschen oder unklare Grenzen enthält.
Warum sind Sprecherkennzeichnungen und Zeitstempel für juristische und wissenschaftliche Anwendungsfälle entscheidend?
In Gerichtsverfahren wie juristischen Aussagen ist Struktur unerlässlich. Klare Sprechernamen, Zeitstempel und konsistente Kennzeichnungen erleichtern die Referenzierung von Aussagen und die Überprüfung von Zitaten. Dasselbe gilt für akademische Forschung, Forschungsinterviews und qualitative Forschung, bei der Analysten Aussagen zu exakten Momenten in der Aufnahme zurückverfolgen müssen, ohne das Audio wiederholt abzuspielen.
Wann sollte ich menschliche Transkription statt reiner KI-Transkription wählen?
KI funktioniert gut bei sauberen Aufnahmen, aber menschliche Transkription ist oft notwendig für Wort-für-Wort-Transkription, schlechtes Audio, mehrere Sprecher oder Situationen, die absolute Genauigkeit erfordern. Menschliche Überprüfung hilft beim Entfernen von Füllwörtern, beim Klären unklarer Abschnitte und beim korrekten Anwenden von Rollenkennzeichnungen oder tatsächlichen Namen. Für anspruchsvolle oder professionelle Anforderungen liefert dieser hybride Ansatz zuverlässigere und genauere Transkripte mit weniger Nacharbeit.

Rodoshi Das
Rodoshi hilft SaaS-Marken mit Inhalten zu wachsen, die konvertieren und in SERPs und LLMs aufsteigen. Sie verbringt ihre Tage damit, Tools zu testen, und verwandelt ihre Erfahrungen in spannende Geschichten, die Nutzern helfen, fundierte Kaufentscheidungen zu treffen. Nach Feierabend tauscht sie Dashboards gegen Kriminalromane und Gartentherapie.