Quando as pessoas perguntam se as etiquetas de orador ou as marcas de tempo atrasam a transcrição, normalmente estão a fazer a pergunta errada.
A verdadeira preocupação não é a rapidez com que uma transcrição é entregue, mas quão rapidamente se torna utilizável.
Para entrevistas, gravações jurídicas, investigação académica e legendas, uma transcrição que chega cedo mas carece de estrutura cria mais trabalho do que poupa. Quando os editores revisitam o áudio repetidamente, os ciclos de revisão tornam-se mais longos do que o habitual.
Neste artigo, vou explicar o que realmente afeta a velocidade e a qualidade da transcrição. Também vou abordar se as etiquetas de orador e as marcas de tempo ajudam ou prejudicam. Vamos a isso!
TL;DR
- Les étiquettes de locuteurs et les horodatages ne ralentissent pas significativement le processus de conversion audio en texte ou vidéo en texte. Les deux sont générés automatiquement dans le cadre du pipeline de transcription.
- La vitesse de transcription est bien plus influencée par la qualité audio, le nombre de locuteurs, les chevauchements de parole et l’accent que par l’ajout de structure.
- Les étiquettes de locuteurs réduisent le temps de relecture en facilitant le suivi des conversations, l’attribution des citations et la navigation dans les transcriptions.
- Les horodatages sont générés pendant la transcription, pas après. Ils font gagner du temps lors de l’édition, du sous-titrage et de la référence.
Que fatores afetam a velocidade e a qualidade da transcrição?
Antes de isolar as etiquetas de orador ou as marcas de tempo, é importante compreender as forças maiores que afetam os resultados da transcrição.
1. Qualidade do áudio e sobreposição de oradores
Um áudio claro é o fator mais determinante para a velocidade e precisão da transcrição.
Ruído de fundo, vozes sobrepostas, má qualidade sonora e níveis de microfone inconsistentes atrasam o reconhecimento automático e aumentam o esforço de revisão.
A sobreposição de fala é particularmente onerosa porque complica tanto a identificação do orador como os limites das frases.
2. Número de oradores e frequência da alternância de turnos
Uma entrevista entre duas pessoas com transições claras comporta-se de forma muito diferente de uma mesa-redonda com trocas rápidas.
À medida que o número de oradores aumenta e a alternância de turnos se torna frequente, a estrutura ganha mais importância. Sem ela, o tempo de revisão cresce rapidamente.
3. Complexidade linguística, sotaques e termos especializados
Vocabulário especializado, fala com sotaque e gravações multilingues aumentam a ocorrência de erros de reconhecimento.
4. Fluxo de trabalho de revisão: transcrição apenas com IA vs. assistida por humanos
A velocidade de entrega inicial é apenas uma parte da equação. As transcrições apenas com IA podem chegar mais depressa, mas os fluxos de trabalho assistidos por humanos reduzem o tempo total ao minimizar revisões e reaudições.
Leia também: Como é medida a precisão da tradução automática
A identificação de oradores atrasa a transcrição?
Adicionar etiquetas de orador parece trabalho extra, por isso é fácil presumir que atrasam o processo. Mas na prática, normalmente não atrasam. O que muda é a quantidade de esforço necessário após a entrega da transcrição.
O que a identificação de oradores (diarização) realmente faz
A identificação de oradores determina quem falou e quando, agrupando os segmentos de fala em conformidade. Os sistemas modernos realizam esta operação durante a transcrição, pelo que não há nenhum passo manual adicional envolvido.
Quando a identificação de oradores pode gerar atrito
Em gravações com muito ruído de fundo e interrupções constantes, ou intervenções muito curtas, a diarização pode exigir verificação adicional. Nestes casos pontuais, a identificação pode acrescentar um ligeiro tempo de processamento ou revisão.
Quando a identificação de oradores reduz o tempo total de entrega
Em conteúdo estruturado como entrevistas, reuniões, depoimentos jurídicos ou investigação qualitativa, as transcrições com etiquetas são mais rápidas de rever e aprovar. Os editores conseguem percorrer o diálogo e atribuir citações com confiança.
Por que é que as transcrições sem etiquetas demoram frequentemente mais a finalizar
Quando os oradores não estão identificados, os revisores compensam manualmente. Reproduzem secções para confirmar quem está a falar, inserem etiquetas eles próprios e verificam as referências cruzadas. O tempo poupado na entrega perde-se durante a finalização.
As marcas de tempo atrasam a transcrição?
Resposta curta: não da forma que a maioria das pessoas assume.
As marcas de tempo são vistas como uma camada adicional acrescentada após a transcrição, algo que aumenta o tempo de processamento.
No entanto, nos sistemas de transcrição modernos, não é assim que funcionam. A informação temporal é gerada à medida que a fala é alinhada com o texto, pelo que as marcas de tempo não introduzem um passo separado por defeito.
Onde a temporização pode afetar o prazo de entrega é na precisão com que essas marcas precisam de se alinhar com o áudio e na quantidade de correção necessária durante a revisão.
Como são geradas as marcas de tempo durante a transcrição
À medida que o áudio é processado, cada segmento falado já está a ser associado a um ponto no tempo.
As marcas de tempo ao nível da frase simplesmente tornam este alinhamento visível. São produzidas automaticamente e não requerem intervenção manual, a menos que o áudio seja pouco claro.
Marcas de tempo ao nível da frase vs. ao nível da palavra
As marcas de tempo ao nível da frase são mais rápidas de rever e cobrem a maioria dos casos de uso, incluindo entrevistas, legendas e documentação.
Por outro lado, as marcas de tempo ao nível da palavra oferecem um controlo mais preciso para edição ou análise avançada, mas exigem um alinhamento mais rigoroso e mais verificação.
De onde vêm os atrasos relacionados com marcas de tempo
Quando ocorrem atrasos, normalmente resultam da revisão e correção do alinhamento.
Má qualidade de áudio ou fala sobreposta com limites de frase pouco claros dificultam a fixação precisa da temporização.
A presença de marcas de tempo não é a causa; a complexidade do áudio é que é.
Por que é que marcas de tempo precisas poupam tempo depois
Marcas de tempo precisas reduzem a necessidade de voltar a ouvir o áudio quando se criam legendas, se consultam materiais jurídicos ou se extraem clips.
Em vez de percorrerem as gravações, as equipas podem saltar diretamente para o momento certo, o que encurta significativamente o tempo de revisão e reutilização.
As marcas de tempo raramente atrasam a transcrição em si. Pelo contrário, tendem a acelerar tudo o que se segue.
Leia também: Os 5 melhores geradores de legendas em 2026
Por que é que remover etiquetas de orador ou marcas de tempo frequentemente custa mais tempo depois
No papel, remover etiquetas de orador ou marcas de tempo parece uma forma de acelerar as coisas. A transcrição chega mais cedo e todas as palavras estão lá. Mas na prática, a estrutura em falta manifesta-se como trabalho extra durante a revisão.
Identificação manual de oradores durante a revisão
Quando faltam etiquetas de orador, os revisores têm de identificar os oradores por conta própria. Isto implica reproduzir secções, associar vozes e manter um registo mental de quem está a falar e onde.
Em gravações mais longas ou conversas em grupo, isto torna-se rapidamente tedioso e inconsistente, ainda mais quando estão envolvidos vários revisores.
Voltar a ouvir o áudio para contexto e referências
Sem marcas de tempo, a transcrição perde a sua ligação direta com o áudio.
Encontrar uma citação, verificar o contexto ou confirmar a redação significa percorrer a gravação manualmente.
O que deveria ser uma consulta rápida transforma-se em reproduções repetidas, acrescentando atrito mesmo às tarefas de revisão mais simples.
Trabalho extra em legendagem, revisão jurídica e análise de investigação
As legendas dependem de uma temporização precisa. As transcrições jurídicas baseiam-se numa atribuição clara. A análise de investigação frequentemente exige ligar declarações a momentos específicos da gravação.
Quando as transcrições carecem de etiquetas de orador ou de marcas de tempo, esta informação tem de ser reconstruída mais tarde, normalmente por alguém que não criou a transcrição original.
Tempo de entrega oculto para além da entrega inicial
O atraso não se manifesta quando a transcrição é entregue. Aparece durante a edição ou a aprovação.
Cada etiqueta ou marca de tempo em falta acrescenta pequenas interrupções que se acumulam entre equipas e ficheiros. Como resultado, o tempo total para concluir uma transcrição prolonga-se.
Na maioria dos fluxos de trabalho, a estrutura acrescentada durante a transcrição reduz o trabalho posterior. Quando essa estrutura é removida, o mesmo trabalho continua a acontecer, apenas mais lentamente e de forma menos previsível.
Leia também: Os 5 melhores serviços de transcrição judicial para equipas jurídicas
Como o HappyScribe lida com etiquetas de orador e marcas de tempo
Quando utiliza o HappyScribe para converter áudio em texto ou converter vídeo em texto, as etiquetas de orador e as marcas de tempo não são adicionadas posteriormente, mas sim fazem parte do processo desde o momento em que carrega o seu ficheiro.
A IA do HappyScribe começa a trabalhar instantaneamente assim que o ficheiro chega ao seu painel de controlo e gera uma transcrição estruturada com indicações temporais integradas à medida que avança.
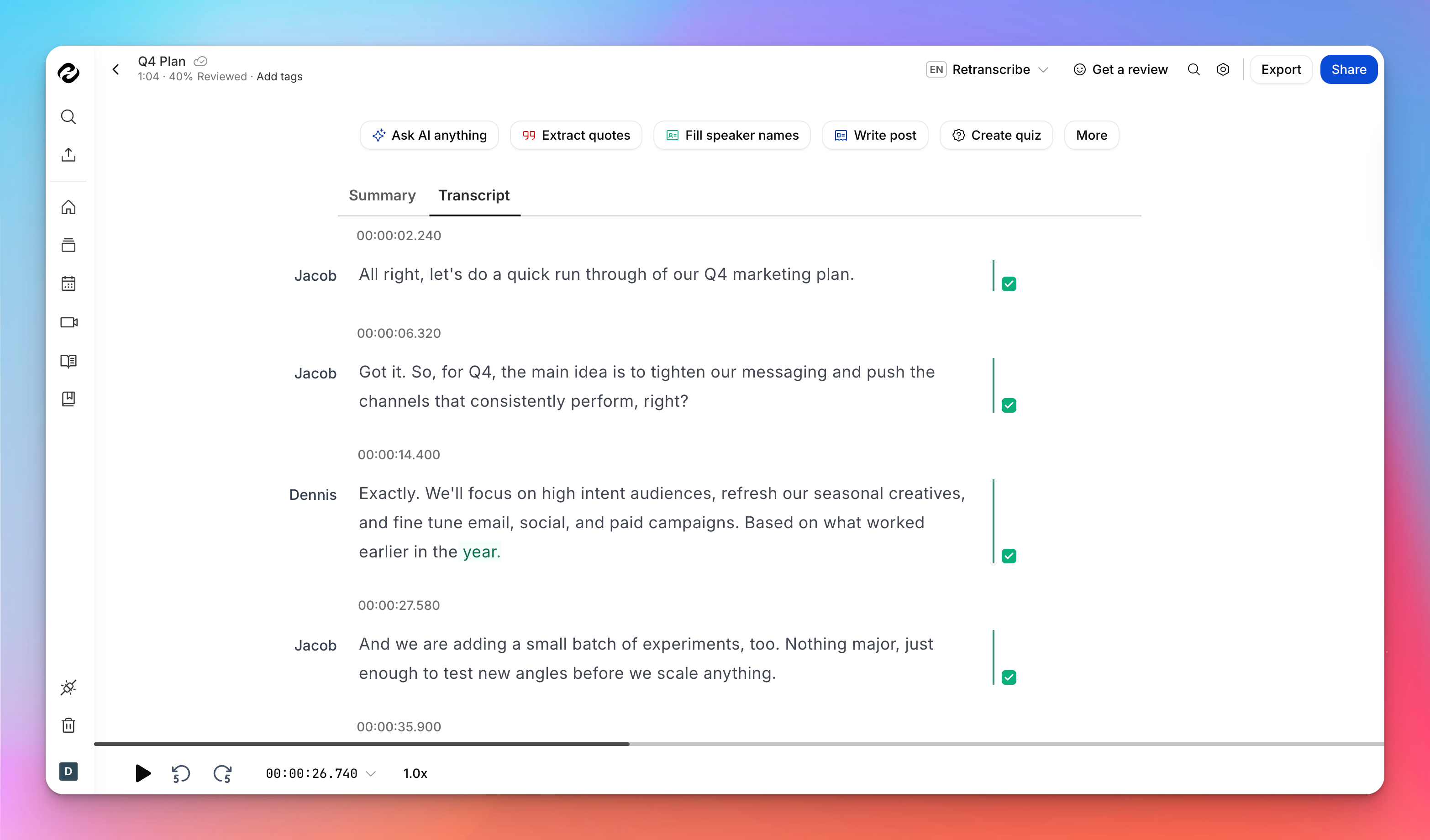
Quanto ao processamento, a transcrição automática do HappyScribe é geralmente concluída em poucos minutos para a maioria dos ficheiros e não exige que fique à espera no navegador enquanto é processada.
Assim que a transcrição inicial é gerada, pode rever, editar e aperfeiçoar diretamente no editor.
As etiquetas de orador já estão aplicadas (pode adicionar nomes de oradores manualmente) e as marcas de tempo estão alinhadas com o áudio, pelo que não precisa de gerir ficheiros separados nem de adicionar estrutura manualmente.
Ambas as funcionalidades servem casos de uso práticos onde a rastreabilidade é crucial, incluindo entrevistas, transcrições de investigação, legendas e documentação jurídica.
Bónus: Transcrições feitas por profissionais
O HappyScribe também oferece transcrição assistida por profissionais como opção.
Neste fluxo de trabalho, linguistas profissionais reveem e aperfeiçoam a transcrição para maior precisão e identificação consistente de oradores. O prazo de entrega é inferior a 24 horas para idiomas comuns como inglês, francês e espanhol.
Pode obter transcrições feitas por profissionais em mais de 130 idiomas.
O verdadeiro problema por detrás da transcrição lenta e como resolvê-lo
As etiquetas de orador e as marcas de tempo não atrasam a transcrição de forma significativa. O que atrasa as equipas é corrigir estruturas em falta posteriormente.
Se se preocupa com o tempo real de entrega, olhe para além da rapidez com que uma transcrição é entregue. Meça quanto tempo demora a revê-la, verificar citações, criar legendas ou reutilizá-la para investigação ou trabalho jurídico. É aí que a estrutura compensa.
A forma mais simples de decidir é testar. Pegue numa gravação real, transcreva-a com as etiquetas de orador e marcas de tempo ativadas e repare em quanto menos tempo gasta a editar e a verificar o contexto.
Se quiser ver como isto funciona na prática, experimente o HappyScribe para o seu próximo ficheiro e avalie o fluxo de trabalho completo, não apenas a velocidade de entrega.
FAQ
Como funciona a identificação de oradores na transcrição de áudio com múltiplos interlocutores?
Na transcrição de áudio com múltiplos oradores, os sistemas modernos de transcrição por IA utilizam aprendizagem automática para detetar diferentes vozes, padrões de fala e pausas na faixa de áudio. Este processo, também conhecido como diarização de oradores, ajuda a identificar os interlocutores mesmo quando há mudanças frequentes. A precisão melhora quando a gravação tem áudio claro e oradores distintos, mas torna-se mais difícil com vozes semelhantes ou fala sobreposta. Utilize ferramentas de transcrição de alta qualidade como o HappyScribe para gerir reuniões com múltiplos oradores.
Na transcrição de áudio com múltiplos oradores, os sistemas modernos de transcrição por IA utilizam aprendizagem automática para detetar diferentes vozes, padrões de fala e pausas na faixa de áudio. Este processo, também conhecido como diarização de oradores, ajuda a identificar os interlocutores mesmo quando há mudanças frequentes. A precisão melhora quando a gravação tem áudio claro e oradores distintos, mas torna-se mais difícil com vozes semelhantes ou fala sobreposta. Utilize ferramentas de transcrição de alta qualidade como o HappyScribe para gerir reuniões com múltiplos oradores.
O que acontece com as etiquetas de orador quando a qualidade de áudio é fraca?
Fraca qualidade de áudio, ruído de fundo intenso ou níveis de microfone inconsistentes dificultam a atribuição de etiquetas de orador com confiança. Nestes casos, as ferramentas de transcrição podem deixar secções pouco claras ou basear-se em pistas contextuais, requerendo depois revisão humana. A utilização de bons microfones externos e a captura de áudio limpo na fonte reduz o trabalho manual e conduz a resultados mais precisos.
Fraca qualidade de áudio, ruído de fundo intenso ou níveis de microfone inconsistentes dificultam a atribuição de etiquetas de orador com confiança. Nestes casos, as ferramentas de transcrição podem deixar secções pouco claras ou basear-se em pistas contextuais, requerendo depois revisão humana. A utilização de bons microfones externos e a captura de áudio limpo na fonte reduz o trabalho manual e conduz a resultados mais precisos.
As etiquetas de orador são úteis para reuniões de negócios e discussões em grupo?
Sim. Em reuniões de negócios, discussões em grupo, painéis de discussão e conversas importantes, as etiquetas de orador evitam confusão quando múltiplas pessoas contribuem. Mesmo etiquetas genéricas como orador A e orador B ajudam os revisores a seguir quem disse o quê. Sem etiquetas, os revisores frequentemente precisam de reproduzir a gravação de áudio para confirmar a atribuição, o que atrasa a revisão.
Como funcionam os carimbos temporais e que formato de carimbo temporal devo escolher?
Os carimbos temporais são gerados para alinhar a fala ao texto. A maioria dos serviços de transcrição oferece diferentes opções de carimbos temporais, como ao nível da frase ou da palavra. Os carimbos ao nível da frase funcionam bem para entrevistas (sejam ficheiros de áudio ou vídeo) e documentação. Os carimbos ao nível da palavra oferecem um controlo mais preciso mas são mais demorados de rever, especialmente quando o ficheiro de áudio contém ruído ou limites pouco claros.
Por que são as etiquetas de orador e os carimbos temporais fundamentais para casos de uso jurídico e de investigação?
Em processos judiciais como deposições legais, a estrutura é essencial. Nomes de orador claros, carimbos temporais e etiquetas consistentes facilitam a referência a testemunhos e a verificação de citações. O mesmo se aplica à investigação académica, entrevistas de investigação e investigação qualitativa, onde os analistas precisam de rastrear declarações até momentos exatos da gravação sem reproduzir repetidamente o áudio.
Quando devo escolher a transcrição humana em vez da transcrição apenas por IA?
A IA funciona bem para gravações limpas, mas a transcrição humana é frequentemente necessária para transcrição literal, áudio de fraca qualidade, múltiplos oradores ou situações que exigem precisão absoluta. A revisão humana ajuda a remover palavras de preenchimento, resolver secções pouco claras e aplicar corretamente etiquetas de função ou nomes reais. Para necessidades profissionais ou de alto risco, esta abordagem híbrida produz transcrições mais fiáveis e precisas com menos retrabalho posterior.

Rodoshi Das
Rodoshi ajuda marcas SaaS a crescer com conteúdo que converte e sobe nas SERPs e LLMs. Passa os seus dias a testar ferramentas e transforma a sua experiência em narrativas interessantes para ajudar os utilizadores a tomar decisões de compra informadas. Fora do trabalho, troca os dashboards por romances policiais e terapia de jardim.