Wanneer mensen vragen of sprekerlabels of tijdstempels de transcriptie vertragen, stellen ze meestal de verkeerde vraag.
De echte zorg is niet hoe snel een transcript wordt geleverd, maar hoe snel het bruikbaar wordt.
Voor interviews, juridische opnamen, academisch onderzoek en ondertitels zorgt een transcript dat snel wordt geleverd maar structuur mist voor meer werk dan het bespaart. Wanneer redacteuren herhaaldelijk het audiomateriaal doornemen, worden de revisiecycli langer dan gebruikelijk.
In dit artikel bespreek ik wat de snelheid en kwaliteit van transcriptie werkelijk beïnvloedt. Ik ga ook in op de vraag of sprekerlabels en tijdstempels helpen of juist hinderen. Laten we beginnen!
TL;DR
- Les étiquettes de locuteurs et les horodatages ne ralentissent pas significativement le processus de conversion audio en texte ou vidéo en texte. Les deux sont générés automatiquement dans le cadre du pipeline de transcription.
- La vitesse de transcription est bien plus influencée par la qualité audio, le nombre de locuteurs, les chevauchements de parole et l’accent que par l’ajout de structure.
- Les étiquettes de locuteurs réduisent le temps de relecture en facilitant le suivi des conversations, l’attribution des citations et la navigation dans les transcriptions.
- Les horodatages sont générés pendant la transcription, pas après. Ils font gagner du temps lors de l’édition, du sous-titrage et de la référence.
Welke factoren beïnvloeden de snelheid en kwaliteit van transcriptie?
Voordat we sprekerlabels of tijdstempels afzonderlijk bekijken, is het belangrijk om de grotere krachten te begrijpen die de resultaten van transcriptie beïnvloeden.
1. Audiokwaliteit en sprekeroverapping
Helder geluid is de belangrijkste factor voor de snelheid en nauwkeurigheid van transcriptie.
Achtergrondgeluid, door elkaar praten, slechte geluidskwaliteit en inconsistente microfoonniveaus vertragen de automatische herkenning en verhogen de revisie-inspanning.
Overlappende spraak is bijzonder kostbaar omdat het zowel de sprekeridentificatie als de zinsafbakening bemoeilijkt.
2. Aantal sprekers en frequentie van beurtwisseling
Een interview met twee personen met duidelijke beurtwisselingen gedraagt zich heel anders dan een snelle paneldiscussie.
Naarmate het aantal sprekers toeneemt en de beurtwisseling frequenter wordt, wordt structuur belangrijker. Zonder structuur neemt de revisietijd snel toe.
3. Talige complexiteit, accenten en vakspecifieke termen
Gespecialiseerde woordenschat, spraak met een accent en meertalige opnamen verhogen het aantal herkenningsfouten.
4. Revisieworkflow: alleen AI-transcriptie vs. menselijk ondersteunde transcriptie
De aanvankelijke leversnelheid is slechts een deel van de vergelijking. Transcripten die uitsluitend door AI zijn gemaakt, komen mogelijk sneller, maar menselijk ondersteunde workflows verkorten de totale doorlooptijd door revisies en herbeluistering te minimaliseren.
Lees ook: Hoe de nauwkeurigheid van machinevertaling wordt gemeten
Vertraagt sprekeridentificatie de transcriptie?
Het toevoegen van sprekerlabels voelt als extra werk, dus het is gemakkelijk om aan te nemen dat ze het proces vertragen. Maar in de praktijk doen ze dat meestal niet. Wat verandert, is de hoeveelheid inspanning die nodig is nadat het transcript is geleverd.
Wat sprekeridentificatie (diarisatie) eigenlijk doet
Sprekeridentificatie bepaalt wie wanneer heeft gesproken en groepeert de spraaksegmenten dienovereenkomstig. Moderne systemen voeren dit uit tijdens de transcriptie, dus er is geen extra handmatige stap nodig.
Wanneer sprekeridentificatie wrijving kan veroorzaken
Bij opnamen met veel achtergrondgeluid en voortdurende onderbrekingen, of heel korte uitingen, kan diarisatie extra verificatie vereisen. In deze randgevallen kan de identificatie voor een geringe extra verwerkings- of revisietijd zorgen.
Wanneer sprekeridentificatie de totale doorlooptijd verkort
Bij gestructureerde content zoals interviews, vergaderingen, juridische getuigenissen of kwalitatief onderzoek worden transcripten met labels sneller gecontroleerd en goedgekeurd. Redacteuren kunnen de dialoog doorlopen en citaten met vertrouwen toewijzen.
Waarom transcripten zonder labels vaak langer duren om af te ronden
Wanneer sprekers niet zijn geïdentificeerd, compenseren revisoren dit handmatig. Ze spelen secties opnieuw af om te bevestigen wie er spreekt, voegen zelf labels in en controleren kruisverwijzingen. De bij de levering bespaarde tijd gaat verloren tijdens het afronden.
Vertragen tijdstempels de transcriptie?
Kort antwoord: niet op de manier die de meeste mensen veronderstellen.
Tijdstempels worden gezien als een extra laag die na de transcriptie wordt toegevoegd, iets dat de verwerkingstijd verlengt.
In moderne transcriptiesystemen werkt het echter niet zo. Tijdinformatie wordt gegenereerd terwijl spraak aan tekst wordt gekoppeld, dus tijdstempels introduceren standaard geen afzonderlijke stap.
Waar timing invloed kan hebben op de doorlooptijd, is de precisie waarmee die tijdstempels met het audiomateriaal moeten overeenkomen en hoeveel correctie er tijdens de revisie nodig is.
Hoe tijdstempels worden gegenereerd tijdens de transcriptie
Terwijl het audiomateriaal wordt verwerkt, wordt elk gesproken segment al gekoppeld aan een moment in de tijd.
Tijdstempels op zinsniveau maken deze koppeling eenvoudig zichtbaar. Ze worden automatisch geproduceerd en vereisen geen handmatige invoer, tenzij het audiomateriaal onduidelijk is.
Tijdstempels op zinsniveau vs. op woordniveau
Tijdstempels op zinsniveau zijn sneller te controleren en dekken de meeste use cases, waaronder interviews, ondertitels en documentatie.
Tijdstempels op woordniveau bieden daarentegen fijnere controle voor geavanceerde bewerking of analyse, maar vereisen een striktere afstemming en meer verificatie.
Waar tijdstempelgerelateerde vertragingen vandaan komen
Wanneer vertragingen optreden, komen ze meestal voort uit het controleren en corrigeren van de afstemming.
Slechte audiokwaliteit of overlappende spraak met onduidelijke zinsgrenzen maken het moeilijker om de timing nauwkeurig vast te leggen.
De aanwezigheid van tijdstempels is niet de oorzaak; de complexiteit van het audiomateriaal is dat wel.
Waarom nauwkeurige tijdstempels later tijd besparen
Nauwkeurige tijdstempels verminderen de noodzaak om het audiomateriaal opnieuw te beluisteren bij het maken van ondertitels, het raadplegen van juridisch materiaal of het extraheren van clips.
In plaats van door opnamen te scrollen, kunnen teams rechtstreeks naar het juiste moment springen, wat de revisie- en hergebruiktijd aanzienlijk verkort.
Tijdstempels vertragen de transcriptie zelf zelden. Integendeel, ze versnellen doorgaans alles wat erna komt.
Lees ook: De 5 beste ondertitelgeneratoren in 2026
Waarom het verwijderen van sprekerlabels of tijdstempels later vaak meer tijd kost
Op papier lijkt het verwijderen van sprekerlabels of tijdstempels een manier om dingen te versnellen. Het transcript komt eerder aan en alle woorden zijn er. Maar in de praktijk manifesteert de ontbrekende structuur zich als extra werk tijdens de revisie.
Handmatige sprekeridentificatie tijdens de revisie
Wanneer sprekerlabels ontbreken, moeten revisoren de sprekers zelf identificeren. Dat houdt in dat ze secties opnieuw afspelen, stemmen koppelen en in hun hoofd bijhouden wie waar spreekt.
Bij langere opnamen of groepsgesprekken wordt dit snel vermoeiend en inconsistent, des te meer wanneer meerdere revisoren betrokken zijn.
Opnieuw luisteren naar audio voor context en referenties
Zonder tijdstempels verliest het transcript de directe link met het audiomateriaal.
Een citaat vinden, de context controleren of de bewoording verifiëren betekent handmatig door de opname scrollen.
Wat een snelle referentie zou moeten zijn, verandert in herhaald afspelen, wat zelfs bij eenvoudige revisietaken voor wrijving zorgt.
Extra werk bij ondertiteling, juridische revisie en onderzoeksanalyse
Ondertitels zijn afhankelijk van nauwkeurige timing. Juridische transcripten zijn gebaseerd op duidelijke toewijzing. Onderzoeksanalyse vereist vaak het koppelen van uitspraken aan specifieke momenten in de opname.
Wanneer transcripten geen sprekerlabels of tijdstempels bevatten, moet deze informatie later worden gereconstrueerd, meestal door iemand die het oorspronkelijke transcript niet heeft gemaakt.
Verborgen doorlooptijd na de initiële levering
De vertraging wordt niet zichtbaar wanneer het transcript wordt geleverd. Die verschijnt tijdens het bewerken of goedkeuren.
Elk ontbrekend label of tijdstempel voegt kleine onderbrekingen toe die zich opstapelen over teams en bestanden heen. Het resultaat is dat de totale tijd om een transcript af te ronden wordt verlengd.
In de meeste workflows vermindert de tijdens de transcriptie toegevoegde structuur het latere werk. Wanneer die structuur wordt verwijderd, vindt hetzelfde werk alsnog plaats, alleen langzamer en minder voorspelbaar.
Lees ook: De 5 beste gerechtelijke transcriptiediensten voor juridische teams
Hoe HappyScribe sprekerlabels en tijdstempels verwerkt
Wanneer u HappyScribe gebruikt om audio naar tekst om te zetten of video naar tekst om te zetten, worden sprekerlabels en tijdstempels niet achteraf toegevoegd, maar maken ze deel uit van het proces vanaf het moment dat u uw bestand uploadt.
De AI van HappyScribe begint direct te werken zodra het bestand in uw dashboard verschijnt en genereert een gestructureerd transcript met geïntegreerde tijdaanduidingen naarmate het vordert.
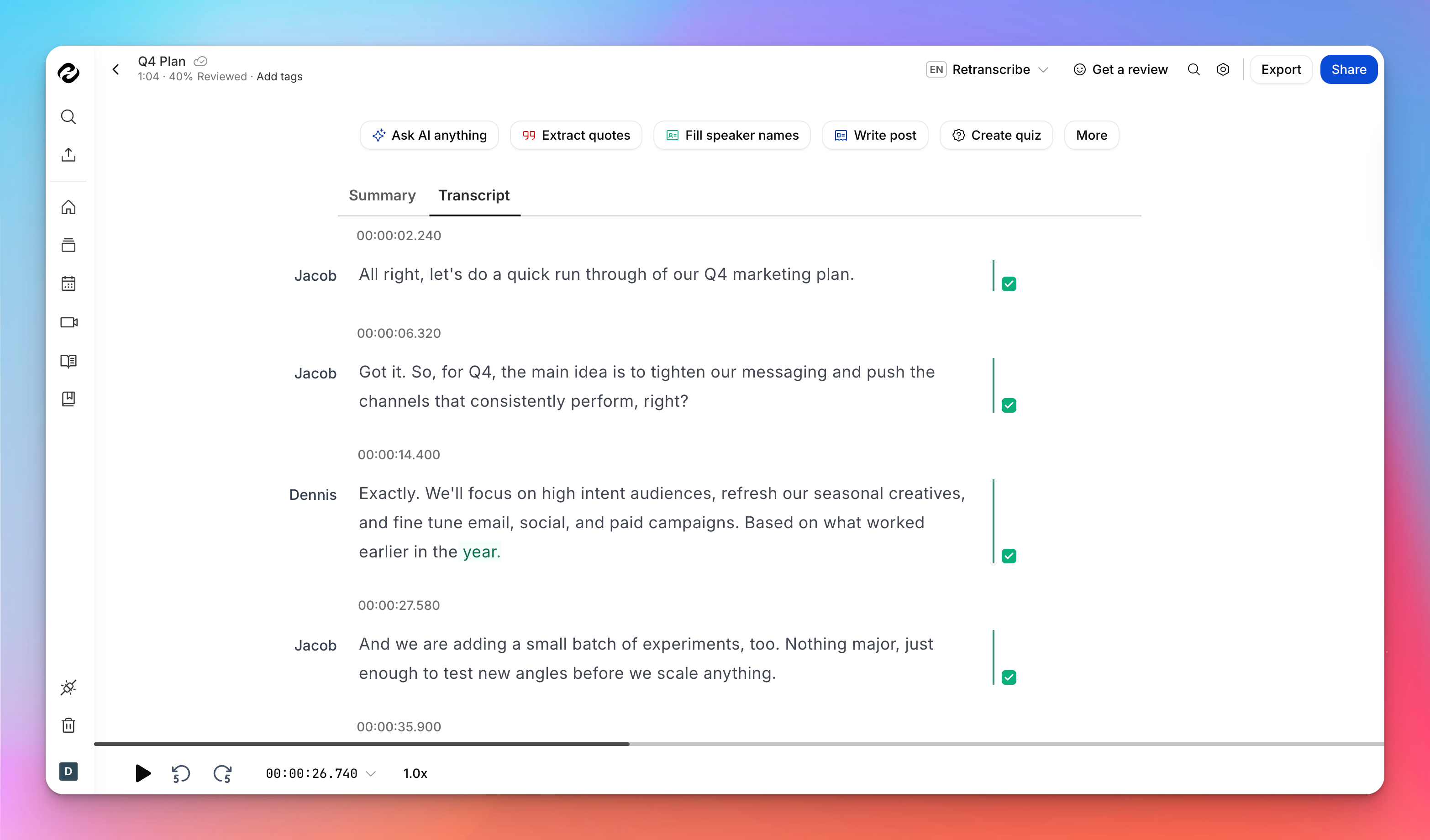
Wat de verwerking betreft, wordt de automatische transcriptie van HappyScribe doorgaans binnen enkele minuten voltooid voor de meeste bestanden en hoeft u niet in de browser te wachten terwijl het wordt verwerkt.
Zodra het eerste transcript is gegenereerd, kunt u het direct in de editor controleren, bewerken en verfijnen.
Sprekerlabels zijn al toegepast (u kunt handmatig sprekernamen toevoegen) en tijdstempels zijn afgestemd op het audiomateriaal, zodat u niet met afzonderlijke bestanden hoeft te werken of handmatig structuur hoeft toe te voegen.
Beide functies dienen praktische use cases waarbij traceerbaarheid cruciaal is, waaronder interviews, onderzoekstranscripten, ondertitels en juridische documentatie.
Bonus: Door mensen gemaakte transcripten
HappyScribe biedt ook menselijk ondersteunde transcriptie als optie.
In deze workflow beoordelen en polijsten professionele taalkundigen het transcript voor hogere nauwkeurigheid en consistente sprekeridentificatie. De doorlooptijd is minder dan 24 uur voor gangbare talen zoals Engels, Frans en Spaans.
U kunt door mensen gemaakte transcripten krijgen in meer dan 130 talen.
Het echte probleem achter trage transcriptie en hoe u het oplost
Sprekerlabels en tijdstempels vertragen de transcriptie niet op een noemenswaardige manier. Wat teams vertraagt, is het achteraf corrigeren van ontbrekende structuren.
Als u geeft om de werkelijke doorlooptijd, kijk dan verder dan hoe snel een transcript wordt geleverd. Meet hoe lang het duurt om het te controleren, citaten te verifiëren, ondertitels te maken of het te hergebruiken voor onderzoek of juridisch werk. Daar betaalt structuur zich terug.
De eenvoudigste manier om te beslissen is het te testen. Neem een echte opname, transcribeer deze met sprekerlabels en tijdstempels ingeschakeld, en merk op hoeveel minder tijd u besteedt aan het bewerken en controleren van de context.
Als u wilt zien hoe dit in de praktijk werkt, probeer HappyScribe voor uw volgende bestand en beoordeel de volledige workflow, niet alleen de leversnelheid.
FAQ
Hoe werkt sprekeridentificatie bij het transcriberen van audio met meerdere sprekers?
Bij het transcriberen van audio met meerdere sprekers gebruiken moderne AI-transcriptiesystemen machine learning om verschillende stemmen, spraakpatronen en pauzes in de audiotrack te detecteren. Dit proces, ook wel sprekerdiarisatie genoemd, helpt sprekers te identificeren zelfs bij frequente sprekerwisselingen. De nauwkeurigheid verbetert wanneer de opname helder geluid en duidelijk te onderscheiden sprekers heeft, maar wordt moeilijker bij gelijkluidende stemmen of overlappende spraak. Gebruik hoogwaardige transcriptietools zoals HappyScribe voor vergaderingen met meerdere sprekers.
Bij het transcriberen van audio met meerdere sprekers gebruiken moderne AI-transcriptiesystemen machine learning om verschillende stemmen, spraakpatronen en pauzes in de audiotrack te detecteren. Dit proces, ook wel sprekerdiarisatie genoemd, helpt sprekers te identificeren zelfs bij frequente sprekerwisselingen. De nauwkeurigheid verbetert wanneer de opname helder geluid en duidelijk te onderscheiden sprekers heeft, maar wordt moeilijker bij gelijkluidende stemmen of overlappende spraak. Gebruik hoogwaardige transcriptietools zoals HappyScribe voor vergaderingen met meerdere sprekers.
Wat gebeurt er met sprekerlabels bij slechte audiokwaliteit?
Slechte audiokwaliteit, zwaar achtergrondgeluid of inconsistente microfoonniveaus maken het moeilijker om sprekerlabels betrouwbaar toe te wijzen. In deze gevallen kunnen transcriptietools onduidelijke secties openlaten of vertrouwen op contextuele aanwijzingen, wat vervolgens menselijke controle vereist. Het gebruik van goede externe microfoons en het vastleggen van schoon geluid bij de bron vermindert handmatig werk en leidt tot nauwkeurigere resultaten.
Slechte audiokwaliteit, zwaar achtergrondgeluid of inconsistente microfoonniveaus maken het moeilijker om sprekerlabels betrouwbaar toe te wijzen. In deze gevallen kunnen transcriptietools onduidelijke secties openlaten of vertrouwen op contextuele aanwijzingen, wat vervolgens menselijke controle vereist. Het gebruik van goede externe microfoons en het vastleggen van schoon geluid bij de bron vermindert handmatig werk en leidt tot nauwkeurigere resultaten.
Zijn sprekerlabels nuttig voor zakelijke vergaderingen en groepsdiscussies?
Ja. Bij zakelijke vergaderingen, groepsdiscussies, paneldiscussies en belangrijke gesprekken voorkomen sprekerlabels verwarring wanneer meerdere personen bijdragen. Zelfs generieke labels zoals spreker A en spreker B helpen reviewers te volgen wie wat heeft gezegd. Zonder labels moeten reviewers vaak de audio-opname opnieuw afspelen om de toewijzing te bevestigen, wat de review vertraagt.
Hoe werken timestamps en welk timestampformaat moet ik kiezen?
Timestamps worden gegenereerd om spraak aan tekst uit te lijnen. De meeste transcriptiediensten bieden verschillende timestampopties, zoals op zins- of woordniveau. Timestamps op zinsniveau werken goed voor interviews (of het nu audio- of videobestanden betreft) en documentatie. Timestamps op woordniveau bieden nauwkeurigere controle maar kosten meer tijd bij het reviewen, vooral wanneer het audiobestand ruis of onduidelijke grenzen bevat.
Waarom zijn sprekerlabels en timestamps essentieel voor juridische en onderzoekstoepassingen?
Bij gerechtelijke procedures zoals juridische getuigenissen is structuur essentieel. Duidelijke sprekernamen, timestamps en consistente labels maken het gemakkelijker om naar getuigenissen te verwijzen en citaten te verifiëren. Hetzelfde geldt voor academisch onderzoek, onderzoeksinterviews en kwalitatief onderzoek, waarbij analisten uitspraken moeten herleiden naar exacte momenten in de opname zonder herhaaldelijk de audio af te spelen.
Wanneer moet ik kiezen voor menselijke transcriptie in plaats van alleen AI-transcriptie?
AI werkt goed voor schone opnames, maar menselijke transcriptie is vaak noodzakelijk voor woordelijke transcriptie, slechte audio, meerdere sprekers of situaties die absolute nauwkeurigheid vereisen. Menselijke controle helpt bij het verwijderen van stopwoorden, het oplossen van onduidelijke secties en het correct toepassen van rollabels of daadwerkelijke namen. Voor veeleisende of professionele behoeften levert deze hybride aanpak betrouwbaardere en nauwkeurigere transcripten op met minder nabewerking.

Rodoshi Das
Rodoshi helpt SaaS-merken te groeien met content die converteert en stijgt in SERP's en LLM's. Ze brengt haar dagen door met het testen van tools en vertaalt haar ervaringen in boeiende verhalen om gebruikers te helpen weloverwogen aankoopbeslissingen te nemen. Na werktijd verruilt ze dashboards voor detectiveromans en tuintherapie.