![Hoe valideert u de nauwkeurigheid van transcriptie in kwalitatief onderzoek? [Inclusief checklist]](/sanity-images/ejgwz1gl/redesign/eb4d668bc95b38859cee00050ec27a38d3e8a075-1536x1024.jpg?auto=format&w=1536.0&rect=0,128,1536,768&h=768)
Een gemiste context in een transcriptie kan een onderzoeksbevinding snel veranderen. Als een deelnemer zegt "ik heb me nooit gesteund gevoeld" en dit wordt getranscribeerd als "ik heb me altijd gesteund gevoeld", kan dat een thema vertekenen en leiden tot een conclusie die uw data niet ondersteunen.
In kwalitatief onderzoek hangt alles wat volgt af van wat er in de transcriptie staat. Daarom is validatie een methodologische vereiste: het zorgt ervoor dat uw onderzoek bestand is tegen toetsing door vakgenoten.
Deze gids behandelt hoe u de nauwkeurigheid van transcriptie in kwalitatief onderzoek valideert: de fouttypen die de validiteit aantasten, een stapsgewijs validatieproces, hoe AI-transcriptie die workflow verandert en een praktische checklist die u vanaf uw volgende project kunt toepassen.
Waarom de nauwkeurigheid van transcriptie belangrijk is in kwalitatief onderzoek
In kwalitatief onderzoek is de transcriptie de primaire dataset waarmee u werkt. Anders dan bij kwantitatief onderzoek, waar ruwe data uit statistieken kan worden gehaald, komen kwalitatieve bevindingen voort uit de woorden die deelnemers daadwerkelijk gebruikten, de formuleringen die ze kozen, de aarzelingen die ze hadden en de manier waarop ze ideeën verwoordden.
1. Transcriptiefouten kunnen zich onopgemerkt verspreiden
Het probleem met kleine fouten is dat ze niet beperkt blijven. Een substitutiefout kan bijvoorbeeld de strekking van een uitspraak omkeren, en een omissie ontneemt een citaat de context die anders tot een thema had geleid.
Als u sprekers in een focusgroep verkeerd toewijst, codeert u uiteindelijk het perspectief van de verkeerde persoon in uw analyse. Deze fouten komen vaker voor dan u denkt en sluipen er ongemerkt in.
2. U bent verantwoordelijk voor het getrouw weergeven van de stemmen van deelnemers
Er is een ethische dimensie die onderzoekers soms onderschatten. Deelnemers geven hun tijd, hun ervaringen en in enquêtes vaak ook hun vertrouwen. Wanneer een transcriptie verkeerd weergeeft wat ze zeiden, vervangt het hun stem door een benadering.
In onderzoek dat zich richt op geleefde ervaringen is die benadering een falen van uw ethische verantwoordelijkheid jegens de mensen die aan uw studie hebben bijgedragen.
3. Nauwkeurige transcripties dienen als een verdedigbaar controlespoor
Als een tijdschriftrecensent of een examinator van een proefschrift vraagt om na te gaan hoe uw thema's uit uw data zijn ontstaan, zijn uw transcripties het eerste wat hij controleert.
Een onnauwkeurige transcriptie verzwakt niet alleen die keten, maar maakt ook het hele analytische proces twijfelachtig.
Soorten transcriptiefouten die de validiteit van onderzoek aantasten
Niet alle transcriptiefouten zien er hetzelfde uit, en sommige zijn moeilijker op te sporen dan andere. Voordat u een transcriptie kunt valideren, moet u weten waarnaar u op zoek bent.
- Substituties treden op wanneer een woord een ander woord vervangt. Dit zijn de gevaarlijkste, omdat ze de betekenis kunnen veranderen zonder er op papier verkeerd uit te zien
- Omissies treden op wanneer woorden of zinsdelen volledig uit de transcriptie wegvallen. Een geschrapte bijzin kan de uitspraak van een deelnemer haar nuance of nuancering ontnemen
- Inserties zijn het tegenovergestelde: woorden die zijn toegevoegd maar nooit zijn uitgesproken. Ze sluipen erin wanneer een transcribent invult wat hij denkt dat er tijdens een onduidelijke passage is gezegd
- Contextuele fouten betreffen gemiste non-verbale signalen zoals pauzes, gelach of vocale nadruk. In woordelijke transcriptie hebben deze analytisch gewicht, en hun afwezigheid kan de data afvlakken
- Verkeerde sprekertoewijzing wijst een uitspraak aan de verkeerde deelnemer toe. In opnames met meerdere sprekers, zoals focusgroepen, corrumpeert dit uw codering bij de bron
- Door vooringenomenheid veroorzaakte fouten treden op wanneer de interpretatie van een transcribent voorrang krijgt op wat er werkelijk is gezegd. Dit gebeurt vaker wanneer de inhoud dubbelzinnig is en de transcribent terugvalt op wat "goed" klinkt in plaats van op wat er is uitgesproken
Hoe u de nauwkeurigheid van transcriptie valideert: stapsgewijze gids
1. Voer een volledige audio-tekstvergelijking uit
Speel de volledige opname af terwijl u de transcriptie van begin tot eind leest. Hier markeert u elke discrepantie tussen wat er werd gezegd en wat er werd getranscribeerd.
Let goed op secties met overlappende spraak, lage audiokwaliteit of emotioneel geladen reacties, want daar concentreren de fouten zich.
Als u in een interactieve transcriptie-editor werkt, kunt u hier veel tijd besparen. De editor markeert tekst synchroon met de audioweergave, geeft sprekers een kleurcode en laat u de afspeelsnelheid aanpassen, zodat u opnames met meerdere deelnemers kunt volgen zonder de draad kwijt te raken.
2. Gebruik de Word Error Rate (WER) voor kwantitatieve benchmarking
De WER geeft u een numerieke maat voor de nauwkeurigheid van transcriptie. De formule is eenvoudig: (substituties + inserties + deleties) / totaal aantal woorden in de referentietranscriptie. Een WER van 0,05 betekent dat 5% van de woorden fouten bevat.
De WER is een belangrijke maatstaf wanneer u door AI gegenereerde transcripties benchmarkt vóór de menselijke controle. Bereken de WER op een steekproef, bepaal de drempel die uw onderzoek kan verdragen en gebruik het resultaat om te beslissen hoeveel handmatige correctie nodig is. De WER vangt geen contextuele fouten of gemiste non-verbale signalen op, dus behandel het als een filter voor de eerste doorloop.
3. Voer member checking uit
Bij member checking stuurt u de transcripties terug naar de deelnemers, zodat zij kunnen nagaan wat er is vastgelegd. Het is een van de vier geloofwaardigheidstechnieken in het betrouwbaarheidskader van Lincoln en Guba, naast langdurige betrokkenheid, peer debriefing en triangulatie.
Het voordeel is duidelijk: deelnemers kunnen fouten opmerken die u zou missen, vooral rond intentie, nadruk of cultureel specifiek taalgebruik. Maar er zijn beperkingen die u moet onthouden. Sommige deelnemers schamen zich wanneer ze hun gesproken taal op schrift zien, terwijl anderen uitspraken die ze in het moment deden willen intrekken of afzwakken. Bouw deze mogelijkheden in uw protocol in, zodat u een duidelijk proces hebt voor het omgaan met herzieningen versus intrekkingen.
4. Gebruik peer debriefing en onafhankelijke controle
Een frisse blik kan u helpen vooroordelen te overwinnen. Laat een tweede onderzoeker of collega een steekproef van transcripties tegen de originele audio controleren, met aandacht voor passages die cruciaal zijn voor uw codering. Als twee beoordelaars verschillende fouten in dezelfde sectie markeren, is dat een signaal dat de passage nader moet worden bekeken.
Deze stap fungeert ook als een betrouwbaarheidscontrole. Wanneer onafhankelijke beoordelaars het eens zijn over de nauwkeurigheid van een transcriptie, versterkt dat de geloofwaardigheid van uw dataset.
5. Standaardiseer een transcriptieprotocol
Als u in een team werkt, definieer dan uw notatieconventies voordat iemand begint te transcriberen. Dit omvat hoe u pauzes, overlappende spraak, onhoorbare segmenten en emotionele toon markeert. Zonder een gedeeld protocol worden inconsistenties tussen transcripties onvermijdelijk, vooral in teamprojecten.
Eftekhari (2024) schetst een praktisch kader voor transcriptieprotocollen in kwalitatief onderzoek, inclusief hoe u de overgang van handmatige naar AI-ondersteunde workflows aanpakt. Als uw team de transcriptie over meerdere mensen verdeelt, houdt een gedocumenteerd protocol uw data consistent.
6. Voer consistentiecontroles uit over transcripties heen
Zodra de afzonderlijke transcripties zijn gevalideerd, controleert u de consistentie over uw volledige dataset. Controleer de namen van deelnemers, plaatsnamen, technische termen, sprekerlabels en tijdstempels om er zeker van te zijn dat alles overeenkomt met de audio.
Deze controles zijn vervelend, maar ze voorkomen verwarring tijdens de codering en maken uw controlespoor makkelijker te volgen.
AI-transcriptie en validatie: hoe de workflow verandert
Wist u dat? Volgens onderzoek van McKinsey gebruikt 79% van de organisaties generatieve AI om werk te versnellen.
AI-transcriptie heeft veranderd hoe onderzoekers met kwalitatieve data omgaan. De kernworkflow is anders, en dat geldt ook voor de fouten waarop u moet letten.
- AI produceert een eerste versie in minuten in plaats van uren, maar de fouten zijn moeilijker op te sporen. Door AI gegenereerde tekst is grammaticaal vloeiend, dus een vervangen woord kan er op papier correct uitzien terwijl het de betekenis van een uitspraak verandert
- De opkomende standaard voor transcriptie in onderzoek is een AI+mens-workflow. AI genereert de transcriptie, en een menselijke beoordelaar valideert deze tegen de originele audio. Geen van beide stappen vervangt de andere
- De menselijke verificatie moet nog steeds dezelfde validatiestappen volgen die hierboven zijn beschreven: een volledige audio-tekstvergelijking, member checking waar passend en consistentiecontroles over transcripties heen
- Als u een cloudgebaseerd AI-hulpmiddel gebruikt, zal uw IRB, REC, IEC of regionale ethische commissie waarschijnlijk vereisen dat u dit in uw formulieren vermeldt. Bevestig voordat u zich aan een platform verbindt waar uw data wordt opgeslagen, of bestanden tijdens verzending en in rust zijn versleuteld, en welke compliancecertificeringen de aanbieder heeft
Tools die u helpen de nauwkeurigheid van transcriptie in onderzoek te verbeteren
HappyScribe
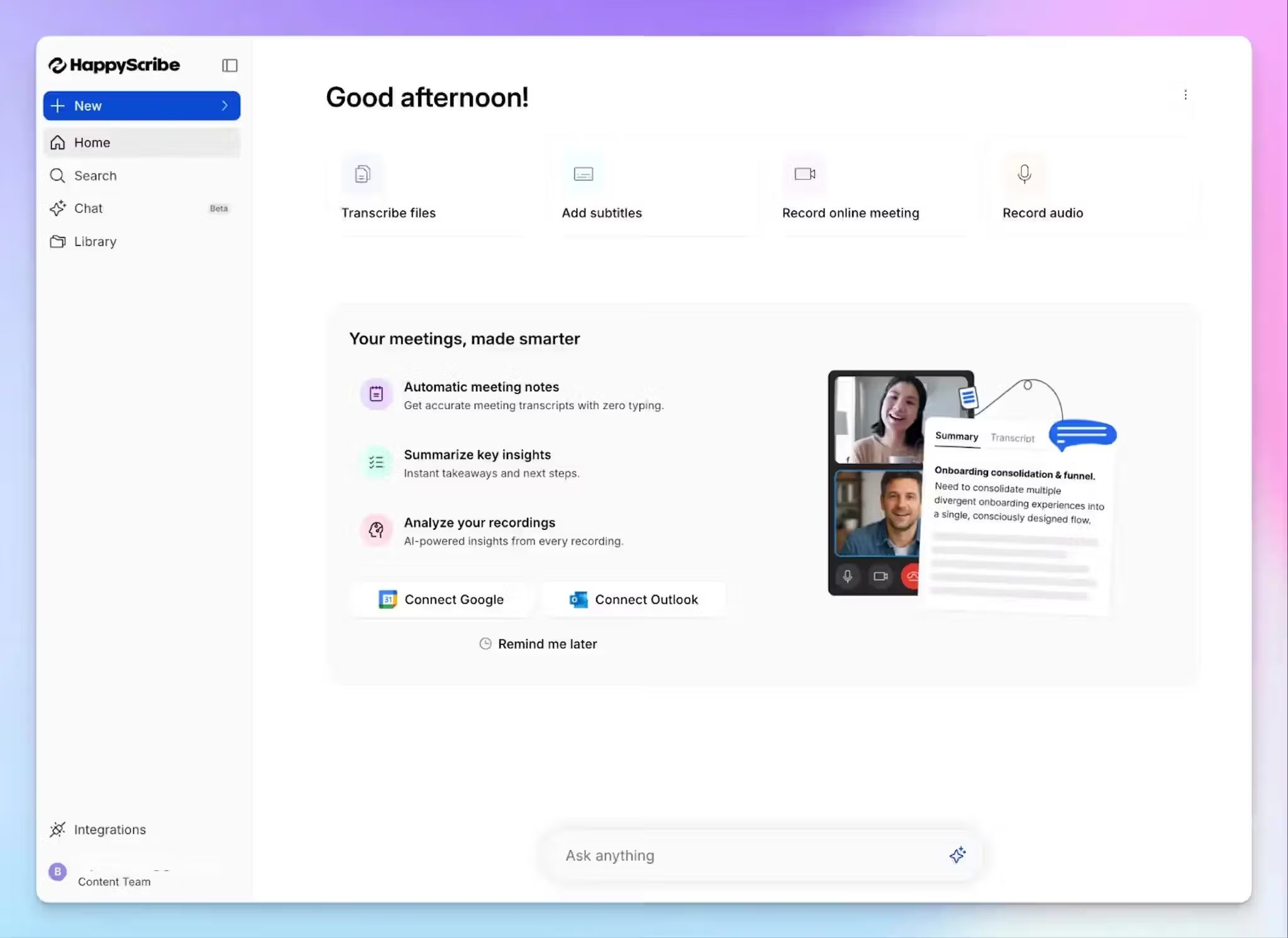
Voor kwalitatieve onderzoekers is het kernprobleem dat transcriptie zowel tijdrovend als van groot belang is. HappyScribe is gebouwd voor onderzoekers die snelheid en flexibiliteit willen zonder in te boeten op nauwkeurigheid.
Met API-, MCP-server- en Zapier-integraties en ondersteuning voor vertaling en ondertiteling helpt HappyScribe u om onderzoeksworkflows uit te breiden zonder voor meer tools te betalen.
Opties voor AI- en menselijke transcriptie
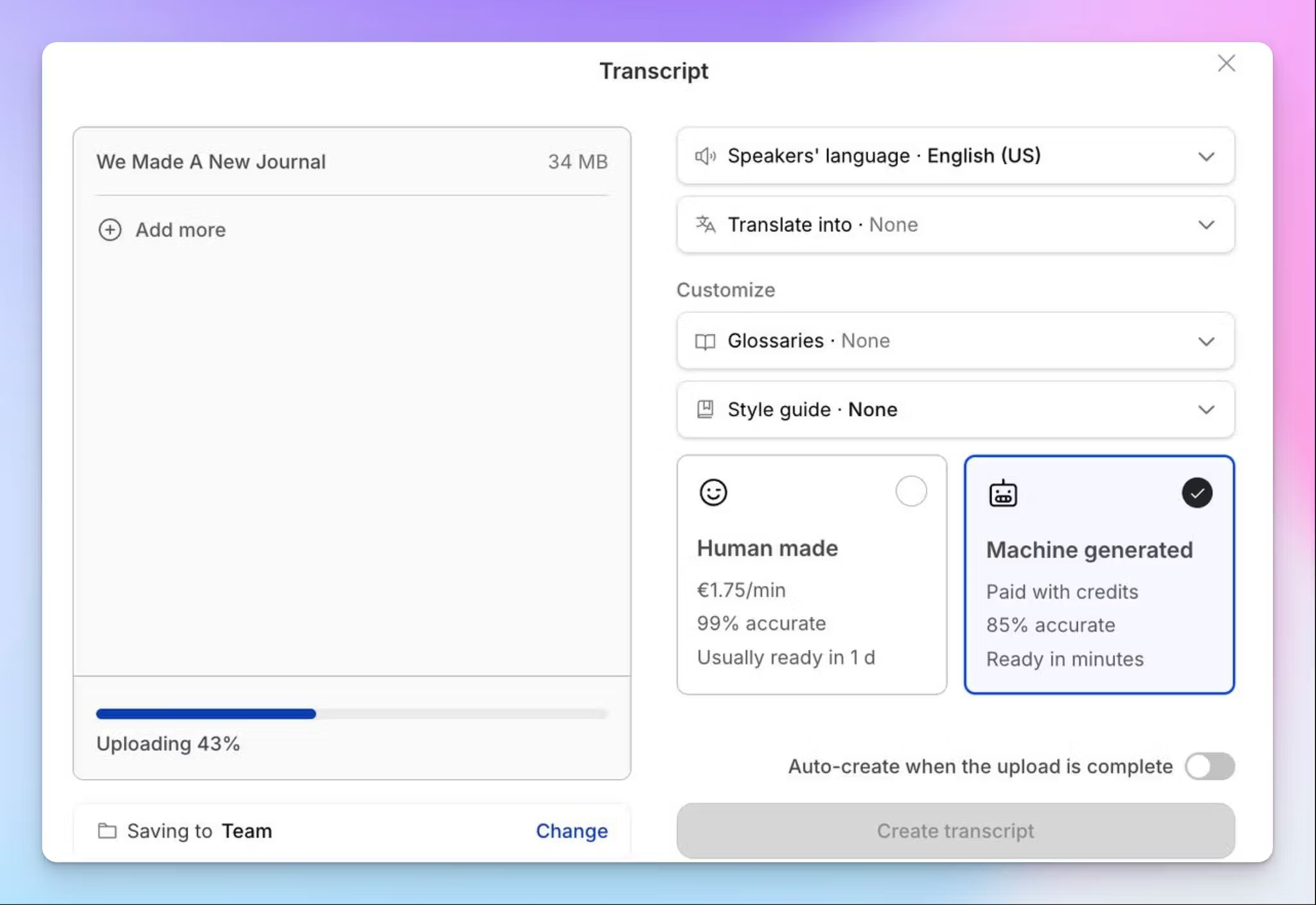
Met HappyScribe kunt u AI-transcripties uitvoeren in meer dan 150 talen om binnen enkele minuten een eerste transcriptie te genereren. Wanneer uw project geverifieerde nauwkeurigheid vereist, kunt u het mediabestand of de transcriptie sturen naar een ervaren taalkundige die het naar 99% nauwkeurigheid brengt. Voor kwalitatieve onderzoekers betekent dit dat u niet hoeft te kiezen tussen snelheid en nauwkeurigheid en zowel met AI als met menselijke experts kunt werken.
Interactieve transcriptie-editor
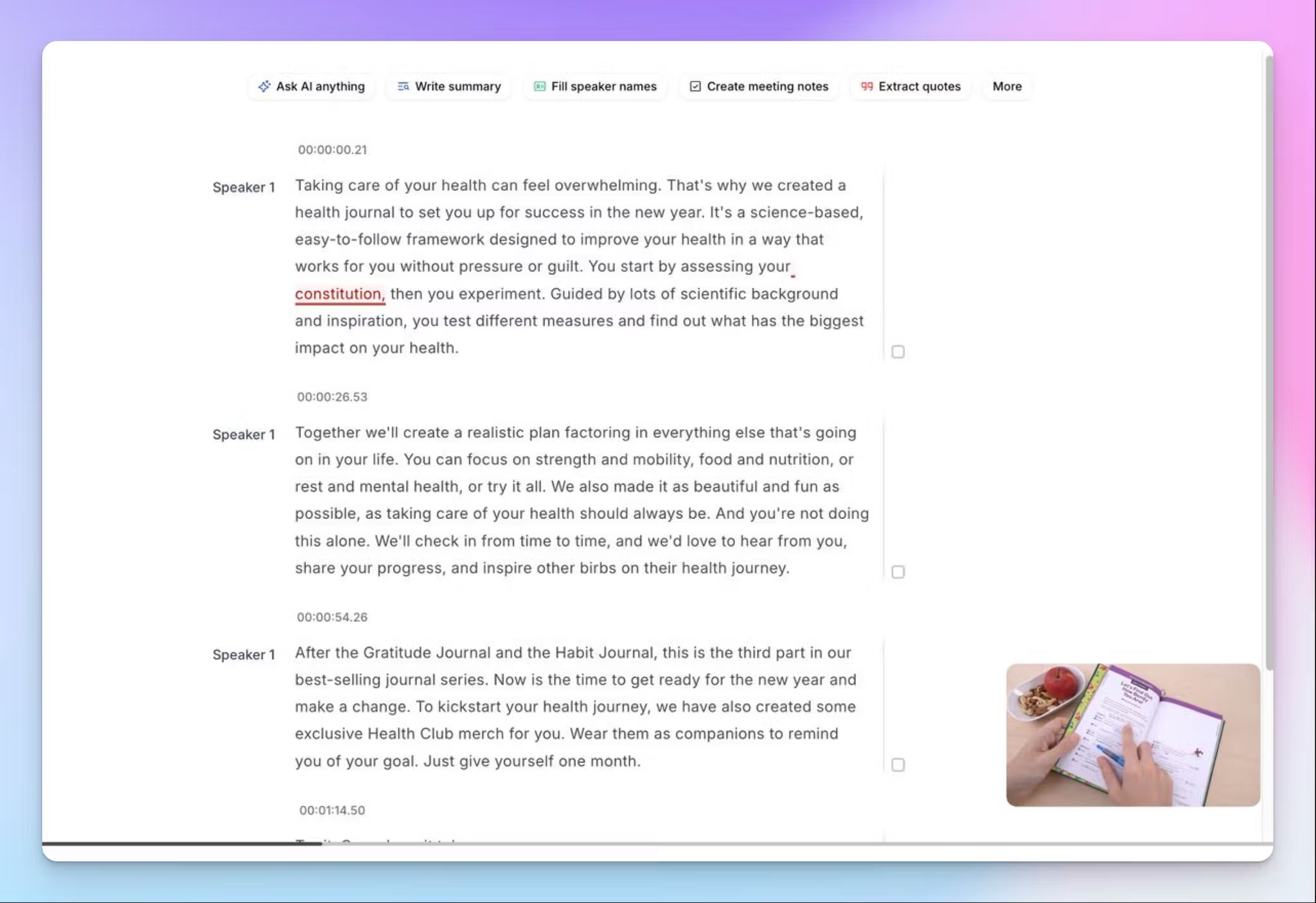
Het validatieproces dat ik eerder schetste, hangt af van de mogelijkheid om audio efficiënt met tekst te vergelijken. Met de editor van HappyScribe kunt u tegelijkertijd luisteren en lezen, de afspeelsnelheid aanpassen, termen zoeken, passages markeren en fouten rechtstreeks in de tekst corrigeren. U kunt ook teamleden uitnodigen, wat handig is voor grotere projecten die meerdere controlerondes doorlopen.
Vind diepere inzichten met AI Chat

Zodra u alle transcriptiegegevens hebt, kunt u HappyScribe AI Chat gebruiken om belangrijke inzichten, observaties en patronen naar boven te halen die u tijdens het doornemen van de transcripties mogelijk hebt gemist. De AI Chat is gebouwd voor diepgaande gesprekken, dus u kunt vragen om alle bestanden te scannen en u te helpen met samenvattingen, concepten en citaten.
Sprekerherkenning en tijdstempels
HappyScribe identificeert en labelt sprekers automatisch door de hele transcriptie heen. Omdat tijdstempels op woordniveau zijn gekoppeld, kunt u elke passage met de originele audio vergelijken zonder de volledige opname door te spoelen.
AVG-conform en SOC 2 Type II gecertificeerd
Als u een ethische aanvraag of een IRB-protocol indient waarbij cloudgebaseerde transcriptie betrokken is, kan u worden gevraagd hoe de gegevens van deelnemers worden opgeslagen en beschermd. HappyScribe beschikt over de SOC 2 Type II-certificering, wat betekent dat het regelmatig door een onafhankelijk team wordt geaudit op beveiliging en systeemintegriteit.
Dankzij AVG-conformiteit en gegevensopslag in de EU hebben deelnemers meer controle over privacy en toestemming. Door deze certificeringen vooraf gedocumenteerd te hebben, verloopt het proces van ethische goedkeuring eenvoudiger.
Andere tools die het overwegen waard zijn voor kwalitatief onderzoek
1. ATLAS.ti
ATLAS.ti is een tool voor de analyse van kwalitatieve data. Het verzorgt codering, themaherkenning en netwerkvisualisatie zodra u al over een schone transcriptie beschikt om mee te werken. Als u HappyScribe of een andere transcriptietool gebruikt om uw transcripties te genereren en te verifiëren, kan ATLAS.ti nuttig zijn voor de analyse.
2. Otter
Otter is een door AI aangedreven transcriptietool die voornamelijk voor vergaderingen is gebouwd. Het neemt gesprekken op via Zoom, Google Meet en Microsoft Teams, genereert transcripties en produceert AI-samenvattingen.
Dat gezegd hebbende, ondersteunt Otter slechts 6 talen, wat een aanzienlijke beperking is voor gebruikers die werken met meertalige interviewdata. Het Pro-abonnement begint bij $16,99/maand maar beperkt u tot 1.200 minuten en 10 bestandsimporten per maand, dus grote databases met vooraf opgenomen interviews zijn niet mogelijk.
3. Rev
De kernkracht van Rev is transcriptie gemaakt door mensen met een geclaimde nauwkeurigheid van 99% en een typische doorlooptijd van 12-24 uur, wat het een betrouwbare optie maakt voor onderzoekers die een volledig menselijke workflow willen. Rev biedt ook AI-transcriptie en bestandsanalyse. Houd er rekening mee dat Rev niet de meest betaalbare optie op de markt is, en als u aan zware projecten werkt, lopen de rekeningen snel op.
Checklist voor de nauwkeurigheid van transcriptie voor kwalitatieve onderzoekers
Gebruik deze checklist als snelle referentie vóór, tijdens en na de transcriptie. Elke stap wordt eerder in deze gids in detail behandeld.
| Fase | Actie |
|---|---|
| Vóór de transcriptie |
|
| Tijdens de transcriptie |
|
| Na de transcriptie |
|
Valideer uw transcripties voordat u erop voortbouwt
Transcriptievalidatie is niet iets wat u één keer doet en daarna vergeet. Het is een gelaagd proces waarbij elke stap opvangt wat de vorige heeft gemist.
Een volledige audio-tekstvergelijking vangt fouten op die de WER niet kan kwantificeren, en member checking brengt verkeerde weergaven aan het licht die zelfs een zorgvuldige beoordelaar niet zou opmerken. Door consistentiecontroles over de dataset uit te voeren, voorkomt u dat kleine discrepanties zich tijdens de codering opstapelen.
Maar een grondig proces werkt alleen als uw tools het ondersteunen. Als u schakelt tussen een transcriptiedienst, een aparte audiospeler en een spreadsheet om correcties bij te houden, duurt de validatie langer en glippen er fouten door de kieren tussen de tools.
HappyScribe brengt transcriptie, verificatie en samenwerking samen in één platform. U kunt AI-transcripties genereren, overschakelen naar menselijke proeflezing wanneer nauwkeurigheid cruciaal is, en uw volledige validatieworkflow binnen de editor uitvoeren.
Veelgestelde vragen over hoe u de nauwkeurigheid van transcriptie in kwalitatief onderzoek valideert
Wat is member checking bij transcriptievalidatie?
Member checking is wanneer u de transcripties terugstuurt naar de deelnemers, zodat zij kunnen nagaan wat er tijdens het interviewproces is vastgelegd. Het is een geloofwaardigheidstechniek uit het betrouwbaarheidskader van Lincoln en Guba, en het helpt u fouten op te sporen die te maken hebben met intentie, nadruk of cultureel specifiek taalgebruik en die een beoordelaar zou kunnen missen. De beperking is dat sommige deelnemers zich ongemakkelijk voelen wanneer ze hun gesproken taal in geschreven vorm zien, en dat anderen uitspraken willen intrekken.
Stel een duidelijk protocol op voor het omgaan met deze situaties voordat u het transcriptieproces begint, zodat u geen ad-hocbeslissingen over herzieningen hoeft te nemen terwijl de transcriptie van het kwalitatieve onderzoek bezig is. Member checking vermindert ook potentiële vooroordelen die kunnen binnensluipen wanneer één onderzoeker bepaalt hoe alle interviews worden weergegeven.
Hoe berekent u de Word Error Rate (WER) voor een transcriptie?
De WER meet hoever een transcriptie afwijkt van een referentieversie. De formule is (substituties + inserties + deleties) / totaal aantal woorden in de referentietranscriptie. Een WER van 0,05 betekent dat 5% van de woorden fouten bevat. Het is het nuttigst voor het benchmarken van door AI gegenereerde transcripties die afhankelijk zijn van spraakherkenning en natuurlijke taalverwerking voordat u overgaat naar de menselijke controle. De WER vangt geen contextuele fouten of gemiste non-verbale signalen op, dus het werkt het best als een filter voor de eerste doorloop voor nauwkeurige transcriptie in plaats van als een volledige validatiemethode. U hebt nog steeds een volledige audio-tekstvergelijking nodig om op te vangen wat de WER mist.
Hoe nauwkeurig is AI-transcriptie voor kwalitatief onderzoek?
De meeste op spraakherkenning gebaseerde transcriptiesoftware levert 85-95% nauwkeurigheid op schone audio-opnames. Dat klinkt hoog, maar in een transcriptie van 10.000 woorden betekent zelfs 5% fouten dat 500 woorden fout zijn, en sommige van die fouten belanden in analytisch cruciale passages. Voor kwalitatief onderzoek, waar de getranscribeerde data de primaire dataset is, is die marge zonder menselijke controle niet acceptabel. HappyScribe lost dit op door u AI-transcriptie te laten uitvoeren voor een snelle eerste versie en vervolgens over te schakelen naar menselijke proeflezing die de nauwkeurigheid naar 99% brengt.
Wat is het verschil tussen woordelijke en intelligente woordelijke transcriptie?
Woordelijke transcriptie legt alles vast: stopwoorden, valse starts, herhalingen, pauzes, gelach en non-verbale communicatie. De intelligente woordelijke transcriptie schoont de tekst op door stopwoorden en herhaling te verwijderen terwijl de betekenis van wat er is gezegd behouden blijft. De juiste keuze hangt af van uw kwalitatieve analysemethode.
Als u een thematische analyse uitvoert waarbij u zoekt naar gemeenschappelijke thema's en patronen tussen deelnemers, volstaat de intelligente woordelijke transcriptie meestal, omdat de data-analyse zich richt op betekenis in plaats van op de manier van uitspreken. En als uw onderzoek afhangt van hoe iets is gezegd, zoals bij conversatieanalyse of discoursanalyse, is de woordelijke transcriptie de enige optie, omdat het verwijderen van stopwoorden de data de details ontneemt die u nodig hebt om te analyseren.
Hoe lang duurt het om een transcriptie van kwalitatief onderzoek te valideren?
Een volledige audio-tekstvergelijking van één interview van 60 minuten duurt doorgaans 2-3 uur als u zorgvuldig controleert. De exacte tijdlijn hangt af van de lengte van de opname, de audiokwaliteit en het aantal validatiestappen in uw protocol. Voeg member checking, peer debriefing en consistentiecontroles over uw dataset toe, en u zit aan aanzienlijk meer tijd per transcriptie.
Voor projecten met grote hoeveelheden interviewtranscripties of videodata kan de validatiefase net zo lang duren als de fase van dataverzameling zelf. Door AI-transcriptie te gebruiken voor de eerste versie wordt de initiële omzetting van gesproken woorden naar tekst teruggebracht tot minuten, wat u meer tijd geeft voor de validatie die uw onderzoeksresultaten beschermt tegen gegevensverlies en onnauwkeurigheid.
Wat moet een transcriptieprotocol bevatten voor kwalitatief onderzoek?
Uw protocol moet de notatieconventies definiëren voordat iemand in het team begint te transcriberen. Documenteer minstens hoe u pauzes, overlappende spraak van meerdere sprekers, onhoorbare segmenten en emotionele toon markeert. Geef aan of u woordelijke of intelligente woordelijke transcriptie gebruikt, en leg uit waarom die keuze past bij uw kwalitatieve analyseaanpak.
Neem regels op voor sprekerlabeling, tijdstempelintervallen en hoe u omgaat met gevoelige inhoud waarvoor ethische overwegingen gelden. Als uw instelling of regelgevende instanties specifieke procedures voor gegevensverwerking voor audio-opnames vereisen, documenteer die dan ook in het protocol.
Een sterk protocol houdt de data die over alle interviews zijn verzameld consistent, wat uw thematische analyse betrouwbaarder maakt en uw controlespoor makkelijker te verdedigen.

Biplab Mazumder
Biplab is a content marketer and writer who helps high-growth brands scale content visibility across AI search channels. His works have been published in HubSpot, Freshworks, Atlassian, SurferSEO, etc. When he's not planning content strategy, he's testing AI content workflows and use cases.





