
De vijf transcriptietypes in kwalitatief onderzoek zijn volledig verbatim, schoon verbatim (intelligent verbatim), bewerkte transcriptie, fonetische transcriptie en Jeffersoniaanse transcriptie. De juiste keuze hangt af van hoe u de analyse aanpakt. Schoon verbatim werkt goed voor thematische analyse en grounded theory, terwijl discoursanalyse en conversatieanalyse volledig verbatim of Jeffersoniaanse conventies vereisen.
Ik bespreek alle soorten in detail en help u de juiste te kiezen voor uw onderzoeksproject.
Waarom het soort transcriptie belangrijker is dan de transcriptiesnelheid
Ik heb ooit een thematische analyse uitgevoerd op 30 uur aan focusgroepopnames die volledig verbatim waren getranscribeerd. Elk stopwoord en elke valse start werd vastgelegd. Hoewel de transcripties grondig waren, waren ze bijna onmogelijk te coderen. Ik moest uren besteden aan het doorworstelen van gestamel en halve zinnen in plaats van patronen te herkennen.
Omdat volledig verbatim alles vastlegt, is het uitstekend voor conversatieanalyse. Maar voor thematisch coderen moet u extra details vermijden die uw analyse vertragen. Ik heb het op de harde manier geleerd.
Daarom kan ik nu met overtuiging zeggen dat het soort transcriptie meer invloed heeft op uw analyse dan de doorlooptijd. Een binnen 48 uur opgeleverd schoon verbatim-transcript bedient een theoriestudie veel beter dan een volledig verbatim-transcript dat van de ene op de andere dag wordt geleverd. Het soort dat u kiest, bepaalt wat in uw studie als gegevens telt, en die beslissing geeft vorm aan hoe u codeert en hoe beoordelaars uw werk waarderen.
📚 Lees ook:
De methodologie van kwalitatief onderzoek en de rol van transcriptie
De vijf soorten transcriptie in kwalitatief onderzoek
Deze vijf soorten lopen uiteen van het vastleggen van elk geluid tot het distilleren van alleen de kernbetekenis. Het succes van uw kwalitatieve datatranscriptie hangt af van het afstemmen van het soort op uw analysemethode.
1. Volledig verbatim-transcriptie
Zoals ik eerder al noemde, legt volledig verbatim elk geluid in de opname vast: stopwoorden, valse starts, gestamel, non-verbale signalen zoals lachen en zuchten, getimede pauzes en overlappende spraak. Niets wordt opgeschoond.
Dit detailniveau is nodig voor methodologieën waarbij hoe iets werd gezegd evenveel gewicht heeft als wat er werd gezegd. Zowel conversatieanalyse als discursieve psychologie behandelen spraakpatronen en presentatie als primaire gegevens. Discoursanalyse vereist het vaak ook, samen met psychologische studies die spraakgedrag onderzoeken.
De keerzijde is tijd. voor één uur audio is 4 tot 8 uur menselijk werk nodig om te transcriberen in volledig verbatim. De transcripties kunnen dicht zijn, en als uw methodologie die mate van detail niet vereist, vertraagt het uw codering.
2. Schoon verbatim (intelligent verbatim) transcriptie
Schoon verbatim verwijdert stopwoorden en valse starts, maar behoudt alle betekenisvolle gesproken inhoud. Het geeft u het beste van twee werelden, waardoor het de standaardoptie is voor de meeste kwalitatieve onderzoeken.
Zowel thematische analyse als grounded theory hebben baat bij schone, goed scanbare transcripties die de focus weer op de betekenis leggen. Fenomenologische studies werken er ook goed mee, vooral wanneer het onderzoek zich richt op de taal van de geleefde ervaring in plaats van op de mechaniek van het spreken. Als u aan een scriptie werkt, is de kans groot dat schoon verbatim is wat uw commissie verwacht.
Maar het kent ook beperkingen. Met een schoon verbatim-transcriptie verliest u gegevens over spraakpatronen. Als aarzelingen of presentatiepatronen belangrijk zijn voor uw kader, bewaart schoon verbatim ze niet. Als u al nadenkt over hoe u uw codering organiseert, het gebruik van thema's en tags tijdens het transcriberen kan u later tijd besparen.
3. Bewerkte transcriptie
Bewerkte transcriptie corrigeert de grammatica en herstructureert zinnen voor de leesbaarheid. Het resultaat leest als een verzorgd essay in plaats van als gesproken taal.
Het komt veel voor in beleidsonderzoek en toegepaste kwalitatieve studies waar transcripties toegankelijk moeten zijn voor niet-gespecialiseerde lezers, zoals stakeholders. Het werkt ook voor rapportklare samenvattingen en voor interviewinhoud die voor het publiek bestemd is.
Dat gezegd hebbende, bewerking verandert de oorspronkelijke stem van de spreker, wat onderzoekersbias kan introduceren. Als de exacte bewoording in uw analyse belangrijker is, is een bewerkte transcriptie niet de juiste keuze.
4. Fonetische transcriptie
Fonetische transcriptie legt vast hoe woorden klinken in plaats van hoe ze worden gespeld, met behulp van IPA (Internationaal Fonetisch Alfabet)-symbolen. Het legt uitspraak en dialect vast op manieren die standaard orthografische transcriptie niet kan.
Fonetische transcriptie is een gespecialiseerd hulpmiddel voor taalkundig onderzoek. Zowel sociolinguïstische studies als fonologische analyse zijn ervan afhankelijk, en het wordt ook gebruikt in onderzoek naar logopedie.
Maar de drempel is hoog. U hebt IPA-training nodig om deze transcripties te maken en te lezen, en de methode wordt zelden buiten de taalkunde gebruikt. De meeste kwalitatieve onderzoekers hebben het niet nodig, tenzij hun studie zich specifiek richt op hoe woorden worden uitgesproken.
5. Jeffersoniaanse transcriptie
Jeffersoniaanse transcriptie is een notatiesysteem dat boven op volledig verbatim-transcriptie wordt gelegd. Ontwikkeld door Gail Jefferson voor conversatieanalyse (CA), gebruikt het gestandaardiseerde symbolen om interactionele details te coderen die platte tekst niet kan vastleggen.
Hier zijn enkele van de belangrijkste conventies:
| Symbool | Betekenis |
|---|---|
| [ ] | Overlappende spraak |
| (0.5) | Pauzeduur in seconden |
| ↑ ↓ | Toonhoogtewisseling (omhoog of omlaag) |
| Onderstreping | Nadruk van de spreker |
| = | Aansluiting (geen pauze tussen de beurten) |
Voor de volledige set conventies is Hepburn and Bolden (2017) de standaardreferentie.
Jeffersoniaanse transcriptie kunt u het beste gebruiken voor CA en interactiestudies. Ook toegepaste CA in onderzoek naar gezondheidszorg en onderwijs steunt erop, vooral wanneer beurtwisseling en micro-timing centraal staan in de analyse.
De leercurve is steil en de methode vereist audio van hoge kwaliteit om mee te werken. AI-transcriptietools produceren geen Jeffersoniaanse notatie, dus het werk wordt vrijwel altijd met de hand gedaan.
Het juiste soort transcriptie voor uw studie kiezen: in één oogopslag
Deze tabel koppelt veelvoorkomende kwalitatieve methodologieën aan het soort dat ze het beste bedient:
| Methodologie | Aanbevolen soort | Onderbouwing |
|---|---|---|
| Thematische analyse | Schoon verbatim | Focus op betekenis boven presentatie, leesbaar voor codering |
| Grounded theory | Schoon verbatim | Codering met constante vergelijking werkt sneller zonder ruis van stopwoorden |
| Fenomenologie | Schoon of volledig verbatim | Hangt af van of de taalpatronen van de geleefde ervaring centraal staan |
| Discoursanalyse | Volledig verbatim | Presentatie- en aarzelingspatronen worden direct gecodeerd |
| Conversatieanalyse | Jeffersoniaans | Beurtwisseling, overlap en micro-timing zijn de gegevens |
| Narratieve analyse | Volledig of schoon verbatim | De verhaalstructuur is de prioriteit; stopwoorden meestal niet |
| Sociolinguïstische studie | Fonetisch of Jeffersoniaans | Uitspraak, accent en dialect zijn de onderzoeksfocus |
Als u niet zeker weet waar uw studie onder valt, kunnen drie vragen u helpen beslissen:
- Heeft hoe iets werd gezegd evenveel gewicht als wat er werd gezegd?
- Moeten niet-specialisten (stakeholders, beoordelaars, financiers) de transcripties lezen?
- Wat is uw budget en tijdlijn voor de transcriptie?
AI-transcriptie in kwalitatief onderzoek: is het de juiste keuze?
Handmatige transcriptie is een van de grootste tijdvreters in kwalitatief onderzoek. Als uw studie om schoon verbatim-transcriptie vraagt, hoeft u het niet meer met de hand te doen. AI-transcriptietools leveren nu een schoon verbatim-resultaat met meer dan 95 % nauwkeurigheid voor heldere opnames met één spreker. Dat is nauwkeurig genoeg om als werkconcept te gebruiken.
De nauwkeurigheid daalt alleen wanneer de omstandigheden lastiger worden. Factoren zoals overlappende sprekers, zware accenten en achtergrondgeluid jagen het foutpercentage omhoog, en vakspecifiek jargon kan ASR-modellen in de war brengen die niet zijn getraind op het vocabulaire van uw vakgebied. Sommige tools pakken dit aan met aangepaste woordenlijsten en stijlgidsen.
Maar de academische consensus heeft een evenwichtige aanpak omarmd. AI-transcriptie gevolgd door menselijke verificatie is inmiddels breed geaccepteerd voor peer-reviewed kwalitatief onderzoek. De uitzondering is conversatieanalyse en gedetailleerde discoursanalyse, waar Jeffersoniaanse notatie vereist is en geen enkele AI-tool die kan produceren.

HappyScribe is gebouwd voor de workflows van kwalitatieve onderzoekers. U uploadt de opname, configureert uw uitvoerstijl en krijgt binnen enkele minuten een werktranscript terug met AI-transcriptie in meer dan 150 talen en dialecten.
Als uw opnames regionale accenten en spraakoverlappingen bevatten, kunt u uw bestand of AI-transcript sturen naar professionele taalkundigen die binnen 24 uur transcripties met 99 % nauwkeurigheid leveren. Voor onderzoeksteams die werken met meertalige datasets houdt deze combinatie van AI-snelheid en menselijke nauwkeurigheid het project in beweging zonder de transcriptkwaliteit aan te tasten.
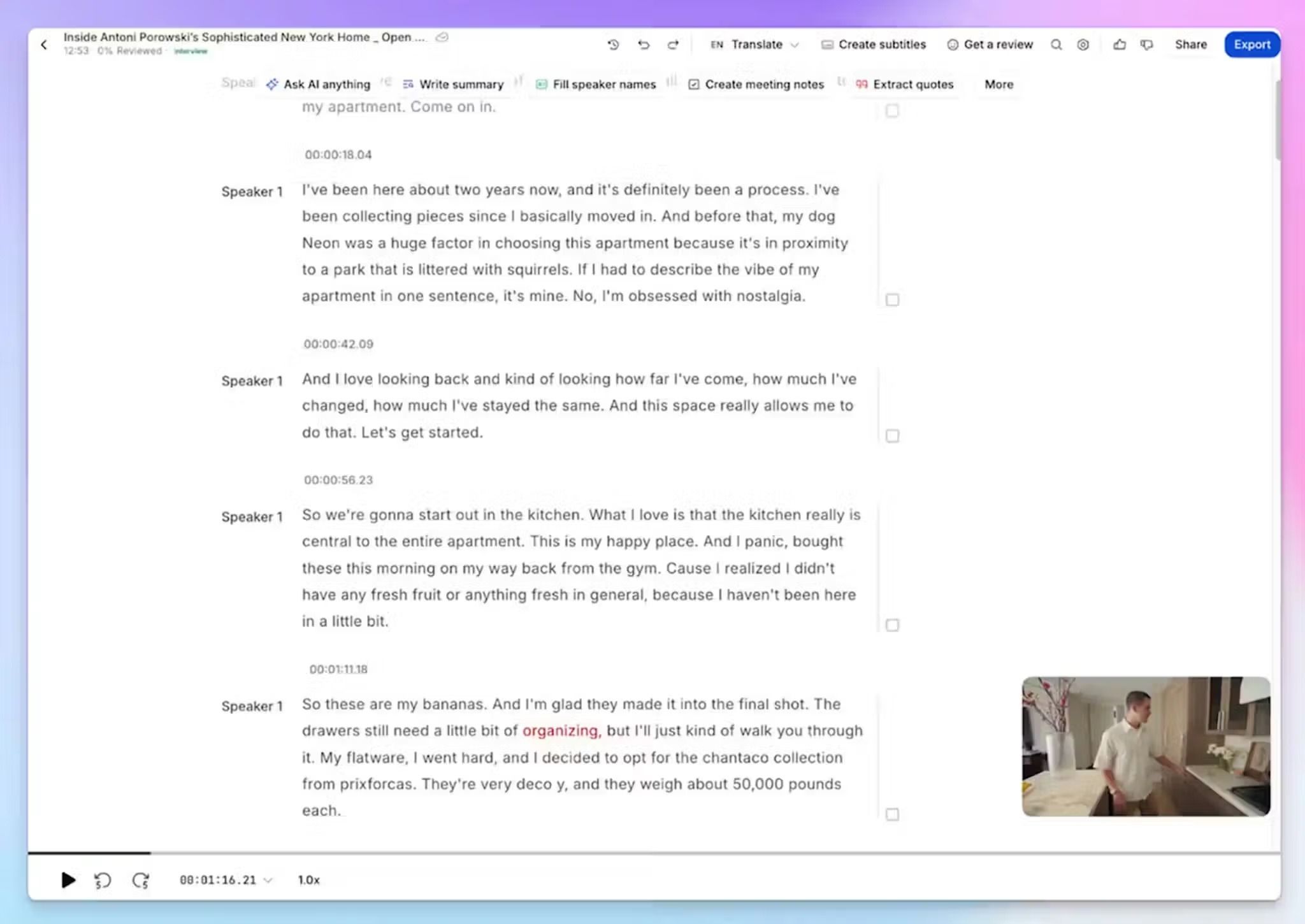
In de interactieve editor vindt de verificatie plaats. U kunt de audio naast het transcript afspelen, naar elke tijdstempel springen en fouten direct in de tekst corrigeren. Sprekerlabels worden automatisch toegepast, dus u hoeft P1 en P2 niet handmatig te taggen over 40 pagina's focusgroepgegevens.

Zodra u alle transcriptgegevens hebt, kunt u de AI Chat gebruiken om belangrijke inzichten, benaderingen en observaties te vinden die u misschien hebt gemist. De AI Chat doorzoekt uw bestanden en transcripties om u te helpen met samenvattingen, citaten en zelfs concept-e-mails. Het fungeert als een onderzoeksassistent, zodat u het analyseproces kunt versnellen.
Beste praktijken voor transcriptie in kwalitatief onderzoek
Als u uitzoekt hoe u kwalitatieve interviews moet transcriberen, gelden deze vijf praktijken ongeacht het soort dat u kiest:
- Bepaal uw soort transcriptie vóór de gegevensverzameling. Documenteer de keuze in uw methodologiehoofdstuk en, indien van toepassing, in uw ethische-commissieprotocol. Halverwege de studie van transcriptiesoort wisselen creëert inconsistenties die tijdens de peer review moeilijk te rechtvaardigen zijn.
- Maak een transcriptieprotocol. Geef aan hoe u omgaat met onduidelijke audio, overlappende sprekers, anderstalige woorden en gevoelige inhoud. Deel dit protocol met iedereen die verder voor het project transcribeert, zodat elk transcript dezelfde conventies volgt.
- Gebruik consistente sprekerlabels en tijdstempels. Of u nu handmatig transcribeert of met AI-transcriptietools, label sprekers consistent ("Interviewer", "P1", "P2"). Voeg tijdstempels toe met regelmatige tussenpozen of op belangrijke momenten. Consistente labeling bespaart uren wanneer u tijdens het coderen naar specifieke passages zoekt.
- Controleer altijd aan de hand van de bronaudio. Zelfs met professionele menselijke transcriptiediensten doet u er goed aan minstens 10 tot 15 % van het transcript steekproefsgewijs te toetsen aan de opname. Fouten stapelen zich tijdens de analyse op als ze niet vroeg worden opgemerkt.
- Anonimiseer tijdens het transcriberen, niet erna. Vervang namen, locaties en andere identificerende gegevens terwijl u transcribeert. Als u later een eenvoudig zoek-en-vervangfilter toepast, mist u sommige contexten.
Begin met het juiste transcript
Het soort transcriptie is een methodologische beslissing, niet zomaar een opmaakvoorkeur. Stem het af op uw analysemethode voordat u begint met opnemen en documenteer de keuze in uw protocol. Met het juiste soort verdwijnt de transcriptie naar de achtergrond van uw onderzoeksworkflow.
Voor schoon verbatim-transcriptie regelt HappyScribe de volledige workflow van AI-concept tot menselijk geverifieerd transcript.
Veelgestelde vragen over soorten transcriptie in kwalitatief onderzoek
Wat zijn de soorten kwalitatieve onderzoeksmethoden?
De belangrijkste kwalitatieve onderzoeksmethoden zijn interviews, focusgroepen, etnografie, casestudy's en observationele studies. Uw onderzoeksdoelen bepalen welke methode u moet kiezen. Interviews werken het best wanneer u een genuanceerd begrip van individuele ervaringen nodig hebt, terwijl focusgroepen gedeelde perspectieven en groepsdynamiek aan het licht brengen.
De meeste van deze methoden leveren onderzoeksgegevens op in de vorm van audio-opnames of videobestanden, niet de gestructureerde kwantitatieve gegevens die u in een spreadsheet kunt zetten. Het transcriptieproces zet die ruwe gegevens om in geschreven tekst die u kunt coderen en ordenen in datasegmenten voor kwalitatieve analyse. Daardoor bepaalt de kwaliteit van uw getranscribeerde gegevens rechtstreeks de belangrijke inzichten die u uit uw onderzoeksresultaten kunt halen.
Wat zijn de vijf soorten transcriptie in kwalitatief onderzoek?
De vijf soorten zijn volledig verbatim, schoon verbatim (ook wel intelligente transcriptie genoemd), bewerkte transcriptie, fonetische transcriptie en Jeffersoniaanse transcriptie. Volledig verbatim legt elk geluid vast, inclusief stopwoorden en pauzes, terwijl schoon verbatim die stopwoorden verwijdert maar alle betekenisvolle inhoud behoudt. Bewerkte transcriptie herstructureert de spraak voor de leesbaarheid, en fonetische transcriptie gebruikt IPA-symbolen om de uitspraak vast te leggen. Jeffersoniaanse transcriptie voegt notatie voor overlap, toonhoogte en timing toe boven op het volledige verbatim.
Schoon verbatim is de standaardoptie voor de meeste kwalitatieve onderzoeken. Volledig verbatim en Jeffersoniaans zijn voorbehouden aan conversatieanalyse en discoursanalyse, waar presentatiepatronen deel uitmaken van de onderzoeksgegevens.
Hoe kiest u het juiste soort transcriptie voor onderzoek?
Begin met uw analysemethode. Als u een thematische analyse of grounded theory uitvoert, geeft schoon verbatim u onderzoekstranscripties waarmee u eenvoudig waardevolle inzichten kunt halen zonder u door stopwoorden heen te worstelen. Als uw studie spraakpatronen of beurtwisseling onderzoekt, zijn volledig verbatim of Jeffersoniaanse transcriptie de betere keuze.
Twee praktische factoren beperken het verder: of uw onderzoeksdoelen gegevens over spraakpatronen vereisen en of niet-specialisten de transcripties zullen lezen. Als u met videobestanden of videogegevens werkt, controleer dan of uw transcriptietool het formaat ondersteunt. Voor projecten met gevoelige gegevens kiest u een platform met sterke privacycontroles. HappyScribe is AVG-conform en SOC 2 Type 2 gecertificeerd, wat de meeste eisen van ethische commissies dekt.
Is een verbatim-transcript het beste voor kwalitatief onderzoek?
Niet altijd. Volledig verbatim legt elke uiting vast, waardoor het onmisbaar is voor conversatieanalyse en discoursanalyse. Maar voor thematische analyse en grounded theory is schoon verbatim de betere keuze. Het verwijdert stopwoorden en valse starts, zodat uw getranscribeerde gegevens makkelijker te coderen en te ordenen zijn.
Volledig verbatim kan kwalitatieve gegevensanalyse juist vertragen als uw kader geen gegevens over spraakpatronen gebruikt. Het extra detail veroorzaakt ruis in uw datasegmenten wanneer u een gezamenlijke analyse uitvoert of transcripties deelt met een onderzoeksteam. Kies volledig verbatim alleen wanneer hoe iets werd gezegd net zo belangrijk is als wat er werd gezegd.
Welke transcriptiesoftware werkt het best voor kwalitatief onderzoek?
HappyScribe past goed bij kwalitatief onderzoek omdat het beide kanten van de workflow dekt: automatische transcriptie voor snelheid en een professionele transcriptiedienst voor opnames die menselijke nauwkeurigheid nodig hebben. Het verwerkt audio- en video-uploads, past automatisch sprekerherkenning en tijdstempels toe, en exporteert naar formaten die uw kwalitatieve analysetool kan lezen.
Audiokwaliteit is de grootste variabele bij de keuze van transcriptiesoftware. Voor heldere opnames met één spreker levert automatische spraakherkenning op zichzelf sterke resultaten. Voor opnames met slechte audiokwaliteit of overlappende sprekers betekent toegang tot professionele taalkundigen naast de AI-optie dat u niet halverwege het project van platform hoeft te wisselen.
De automatische transcriptiesoftware moet sprekerlabels ondersteunen, u het transcript laten controleren aan de hand van de bronaudio, en videogegevens rechtstreeks verwerken in plaats van te eisen dat u eerst de audio losmaakt.
Kan ik AI-tools gebruiken voor transcriptie in kwalitatief onderzoek?
Ja. AI-tools gebruiken automatische spraakherkenning om een audio-opname binnen enkele minuten om te zetten in geschreven tekst. Voor heldere opnames met één spreker en een goede audiokwaliteit loopt de nauwkeurigheid op tot meer dan 95 %.
Het resultaat werkt het best als eerste concept. U controleert het transcript aan de hand van de bronaudio, corrigeert fouten, en de transcriptietaak is klaar in een fractie van de tijd die het met de hand zou kosten. Deze hybride aanpak is inmiddels breed geaccepteerd in peer-reviewed onderzoek.
Maar er zijn grenzen. Slechte audiokwaliteit en overlappende sprekers verlagen de nauwkeurigheid, en voor conversatieanalyse waar Jeffersoniaanse notatie vereist is, zijn menselijke transcribenten nog steeds nodig. HappyScribe combineert automatische transcriptie met deskundige menselijke transcribenten voor opnames die een hogere nauwkeurigheid nodig hebben, waardoor onderzoekers zowel heldere interviews als uitdagende audio in hetzelfde project kunnen verwerken.

Biplab Mazumder
Biplab is a content marketer and writer who helps high-growth brands scale content visibility across AI search channels. His works have been published in HubSpot, Freshworks, Atlassian, SurferSEO, etc. When he's not planning content strategy, he's testing AI content workflows and use cases.





